AIエージェントでコンテンツ生成エンジンを作った話
はじめに
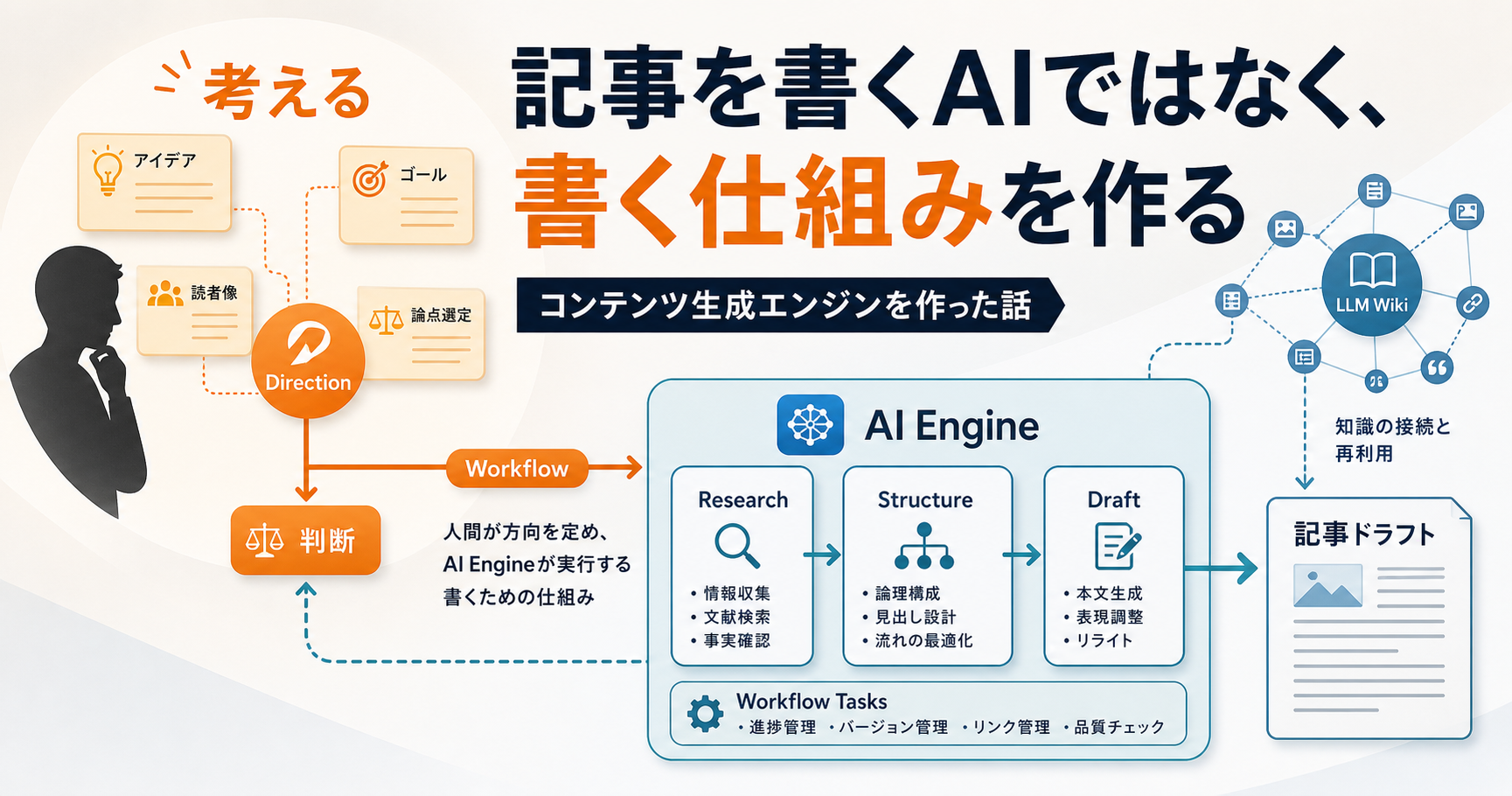
AI が執筆を補助してくれる、ゴーストライターを作った。文章執筆にまつわる一連の作業を、すべて代行ないしサポートしてくれる AI エージェント (Skills) を、各業務フローごとに設計して作ったものだ。
これはほぼ2週間にわたって朝から朝までぶっ通しで続いた、AI問答の記録である。途中で全部捨てたり、また作り直したりもした。
最後に「これからのエンジニアの仕事ってこういう、Agent Skillsとかで業務自動化を組むものになるんじゃないか」という話も少しする。
何を作ったか
ざっくり言うと記事の執筆にまつわる一連の作業を、すべて代行ないしサポートしてくれる AI エージェント (Skills) を、各業務フローごとに設計して作った。大別すると「文章・論理の構成を考える」作業と「関連する文献を探す・読む」工程に分けられる。
ざっくりの工程
文章執筆フローは 4 区分できる。
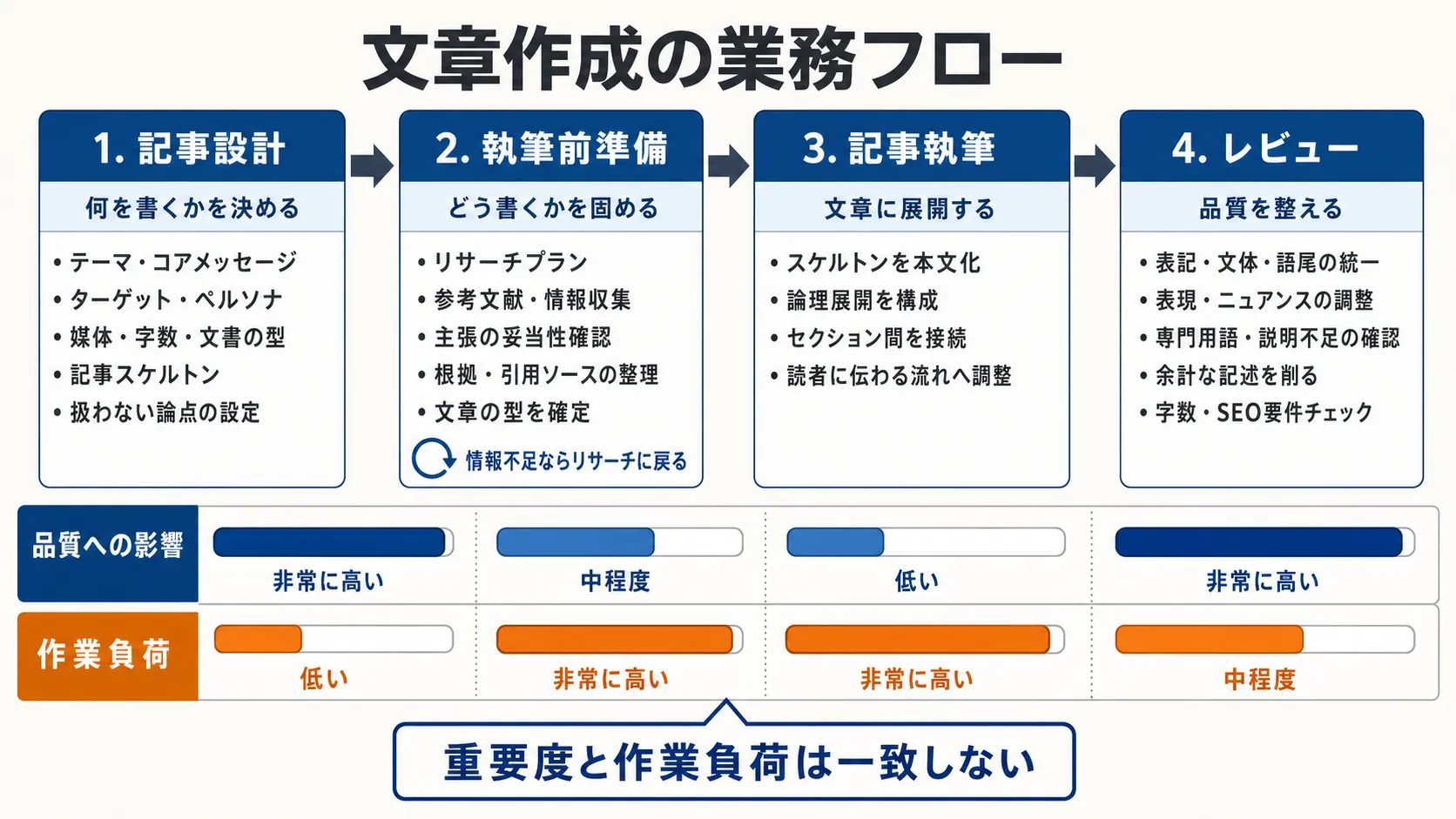
このうち3が所謂「書く (= ライティング. どう書くか)」に相当し、それ以外が何を書くかというディレクションに当たる。今回行ったのは、レビューを除く全行程の AI 化だ。
- 記事設計・計画策定の自動化: 書きたい記事のテーマを決めると記事の設計と企画を生成してくれる
- 文献収集・選別の自動化: それを元に手持ちの文献リストから情報収集し、記事に関連が深い事や盛り込めそうなテキストを収集 & 書くのに足りないソースを報告してくれる
- 論理展開構築自動化: 記事の設計に、収集したソースをもとに「ここに、このソースの話を書く」と直接追加してくれる
- 記事を書く作業の自動化: 最後はそれらをもとに記事を書いてくれる
各フローは Agent Skills が業務手順を保持し、それぞれ担当している。つまりはレビュー・添削を除くすべての工程でラクをしつつ、品質の保証だけ人間が集中してやればいい、という状態まで持っていきたかった。
LLM Wiki に接続されたコンテンツ生成エンジン
LLM Wiki とは
人工知能研究の天才にして OpenAI の共同設立者のひとり Andrej Karpathy が提唱した Obsidian wiki のこと。X の投稿から爆発的に広まり、現在はそこから発展した Obsidian llm-wiki としてコミュニティが OSS で研究を進めている (参照)。
知識・ナレッジ を一次情報のまま放置せず、能動的に活用するための仕組みである。類型として NotebookLM があるが、あちらが検索・要約など知識の抽出を重点としているのに対し、LLM-wiki はナレッジグラフのような情報間の「濃い」繋がりや関連性を生むことを重点としている。
LLM Wiki 直結の三層構造
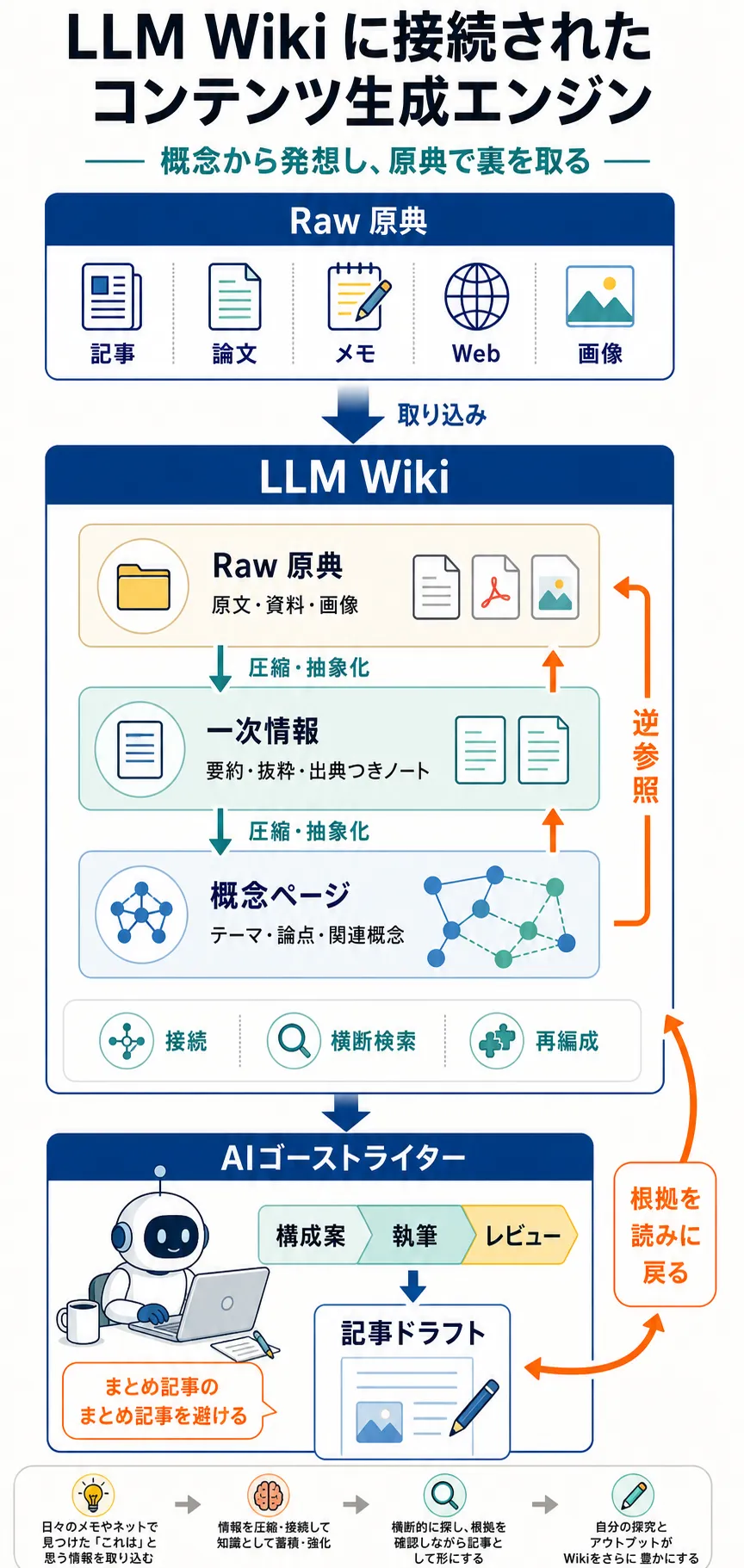
Karpathy の LLM wiki は Raw (原典) → 要約となる wiki 内 1 次情報 → 概念ページ の段階的に情報を圧縮・抽象化する。文章を書く上では Raw を参照したいので、この構造を拡張し、概念ページ → 一次情報 → 原典 と逆順でたどれるようにした。
「まとめ記事のまとめ記事」を AI が書かないようにする配慮・調整だ。情報が薄いとハルシネーション起こしやすくなるしね。
無から有が生まれることはない。日頃からのメモやネットで見つけた「これは」と思う情報を日常的に取り込んでいるとして、自分の書きたいことやアイデアの水源はすべてそれらの中から発現しているわけだ。なので何か「書きたい」と思った時に、その根拠となるデータや裏付けになるような資料の殆どは Wiki の中を探せば眠っているわけだ。
情報同士の接続・横断的な検索はまさしく LLM Wiki の最も得意とする部分。それを活かさないわけにはいかない。
業務 AI 化のテスト
単なるツール利用 (ChatGPTに聞く、画像を作ってもらう、検索を代行する、ファイルを操作するetc) ではなく、業務フロー側を AI ネイティブに作り替える試みである。
地下に潜ってる身としては他所の業務の AI 化を (業務内で) 提案できる機会はあまりない。あったとしても、デモンストレーションとして「AI を業務に組み込む」事例を自分のドメインで実演する必要があった。仮説を頭の中だけで持っていても証明にならないし、自分のドメインで成立しないなら、他ドメインでも成立しない。
また個人に最適化しただけでは業務の AI 化とは呼べず、組織への導入提案としては問題が色濃く残る。誰が使っても同じような品質を出力できる仕組みを設計開発する、というのは今回の非常に重要なテーマだ。
なぜ作ったか
一番大きな理由は、これからのエンジニアの役割は、ソフトウェアを設計することではなく、AI を中心に据えた特定ドメインの業務フローを再設計することになる という仮説の実証実験だ。
それを私が比較的詳しい文章執筆ドメインを対象に、文章執筆フローの一切を Agent 化・だれでも再現できる仕組みとして構築した記録だ。それ以外の動機は文章執筆にまつわる個人的なものである。
なぜ文章執筆ドメインを選んだか
これは「特定ドメインの業務フローを再設計する」ための選択だ。自分が比較的詳しくて、それなりに複雑なドメインだったから。
文章を書くというのはちゃんとやろうとするとなかなか複雑で、非常に多くのリソースと多角的なレビューが必要な作業だ。かつ「書く」にしても「ディレクションする」にしても個人の影響が大きい。だから業務の AI 化・AI 導入による入出力品質の一定水準化の事例の提示対象としても適切かなと。
書きかけのテキスト 100 Over 問題
書きかけ記事 100 単位の死蔵問題、書きたいことや重要な核心だけ並べて、文章を完成まで持っていけない。公開されていない = どこにも存在していないということなので、時間と思考をゴミ箱に放り投げてるのと同じ。文章を完成まで持っていける仕組みを作って生産性向上・対外的な発信力を高めたいという目的があった。
なにより問題なのが、私が完成しない長文生産マシーンだということ。適当に日記を書いても 1500 字は下らず、ひどいときは日記で 5000 字を超えるような人間がまともに (対外的な) 文章を書こうとすると、暗黙知や前提・背景の説明、根拠や出典の説明、別の問題が生じる。
具体例として、Web制作の仕事でデザイナーとトラブった時の分厚い知見があり、それが一般化できるものだったのでエンジニア-デザイナー間の共通言語として浸透すればいいなと書き始めた記事があった。下書きで1万字を超え、殴り書きの積み重ねでトピックもばらばらになったまま。これを他人向けに整形しようとすると倍以上に膨れ上がるし画像の準備とか話の動線を設計し直したりだとかで途方もない労力が発生して挫折、お蔵入りしたまま (尤もデザインがそのままコードになってしまう時代が来てしまったので、これはどの道お蔵入りになりそうだが…)。
万年こういう有様なのでいっそ書くのをやめるか、書いたものが死蔵されない仕組みを作らなければ時間の浪費が解決しない。書ききるか、書くのをやめるか、という必要性があった。
AI で記事一発生成できる時代にわざわざ作る理由
文章を書くというのは本来内向的な行為だ。AI が自動で文章を書く時代だからこそ、人間が文章を書くための AI があってもいいのではないか、というのが私の持論である。
持論を体現するように、このエンジンは 考えないといけない事をしっかり考えないと、次のフローに進めない ように意図的に設計されている。頭を使わなければいけない重要な部分にはしっかりと力を入れ、作業タスクに分類される部分は全部自動化する、という区分けだ。一見記事執筆を自動化したという話と矛盾するようだが、これはポリシーに基づいた設計判断である。
「べつに記事なんて、難しいことしなくても AI に Prompt (Skills) 1 つ渡せば書いてくれるじゃないか」と言われると正直否定するのが難しい。実際ニュース記事や SNS のバズ投稿を自動収集してそれを元に自動で記事を無限生成する、みたいな話はZennやらX (旧Twitter) などでいくらでも出てくる。
しかし書くことによって得られる自分の思考を深めるだとか、確認するだとかという内向的な行いは、一発生成の要約記事では生まれない。その結果出来上がるのが私の頭の中にあったことの説明なのか、動くソフトウェアなのかの違いでしかなく、頭の中にあるものを取り出すための行為という点でプログラムを書くこととの違いはない。だからこそ「考えること」と「書くという行為 (= 作業)」を分離できるエージェントは切実に欲しかった。
2週間ぶっ通しの開発記録
最初に作ろうとしたのはライティングの業務フロー・執筆マニュアルを土台にした、初期案提示を除く全行程の AI 化だった。人間が手を加えるのは全体で 2〜3 割ぐらいになればいいなと考えていた。進行はプログラマライクに機能要件を定義し、簡単な進捗管理表と詳細な機能設計書 (98% は AI が書いている) で詰めていく方式である。最終的にはベルトコンベアがスムーズに流れていくような仕組みではなくなったが、満足なものとなった。
(備考: 前半2セクションは抽象論・仮説論考と結果提示のみでほぼ画像などなし)
出発点と最初の全廃棄 (2026-04-15〜04-18)
出発点
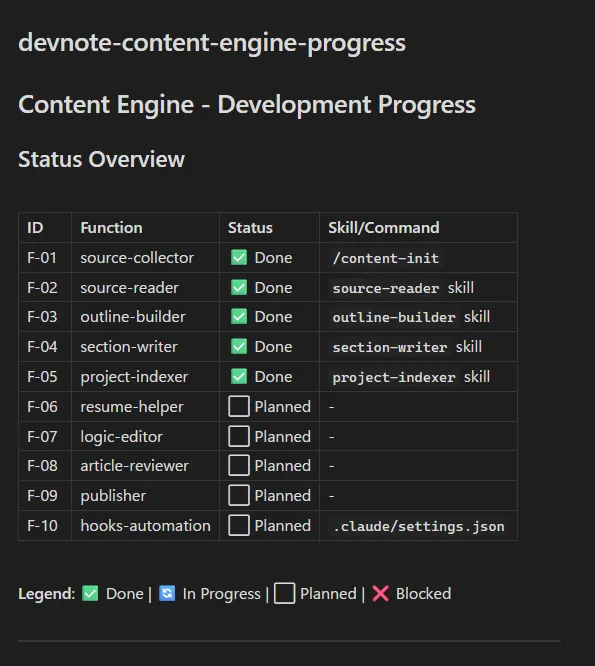
ざっくりと企画だけ立てて開発ボードを作った。機能要件を定義して F-XX という ID で管理していった。この方針は最後までうまく機能した。
最初に計画した機能群は、思いついた当初は「文献を読んで、それから書くというのを自動化する」という方針で検討していた。フローも文献収集 (Wiki への拡張機能) → 文献読解 → 記事設計 (skeleton) 作成 → セクションごとに書かせる、という想定だ。
文献のリストファイル + 記事の設計データを JSON 中心構造でプロトタイプ実装 (F-01, F-03)。集めたソースを source-reader が読み、内容を踏まえて section-writer が記事を書く。この時点ではメタデータは json で考えていた。各セクションで何を書くかと何を根拠に書くのか (ソース) は一体なので json でまとめた方が楽だなと。
当初のプロトタイプ構造:
article-maker/
├── projects/sample-001/
│ ├── 01-sources/{sources.json, raw/}
│ ├── 02-understanding/notes.json
│ ├── 03-reconstruction/themes.json
│ ├── 04-persona/persona.json
│ ├── 05-outline/outline-final.json
│ └── 06-draft/sections/
└── .claude/skills/
├── source-reader/ # Skill 2: 文献読解
├── outline-builder/ # Skill 5: 記事構成作成
└── section-writer/ # Skill 6: セクション執筆同日午後の方針転換 wiki 統合の必要性から JSON → Markdown/YAML 統一へ全廃棄。Obsidian は Markdown を読むためのアプリなので、json が入ると読めない。これでは LLM Wiki 内で完結できなくなるので廃止した。最初は記事データの読込だけやって残りは別途管理でいいかと思っていたが、1 画面で完結しないのは勝手が悪い。
排他性原則 (※ Claude命名. 生成エンジンはLLM Wiki側のテキストに干渉せず、LLM Wikiもコンテンツエンジンの中身や成果物に干渉しないこと) も同日確立した。
F-02 source-reader 廃止 — 言語化問題が技術問題として顕在化 当初の設計では「AI にソースを読ませて、それを元に意見を述べさせる」というものだった。机を離れた際に発想のおかしさに気付いて廃止。「AI に自分の意見を求める Skills 設計は context 概念と整合しない」と判断した。同時にこの時点で「テキストの自動生成」から「AI どうこう以前に、意味のあるテキスト・思考を整理して書くためのツール」という方向性が確定した。
自動化以前に、そもそもの目的の言語化が出来ないとAI化は無理だ、という教訓を得た。
その他の整理
Epistemic Principles 3 原則確立 (Wiki 側での検証済事項の移植):
- 安易な結論回避: 「手持ちの資料から断定できないことは、分からないと書け」という内容。完璧ではないがハルシネーション対策によく効く
- 関心分離: 各 Skills の責務と成果物を区分けし、メンテナンスや個別の評価がしやすいように
- 意味空間の保護: 概念名のバズワード化・未定義語の無批判取り込みを禁ずる
この期間に決まった背骨
- 状態管理 = wiki の状態 (raw → sources → concepts → outputs) を Immutable 寄りに設計、raw は read-only、wiki への変換は append-only
- 関心分離 = 知識 (wiki) / プロセス (Skills) / 起動 (Slash Commands) の三層分離
- skill 同士も役割分離 (issue-builder vs ghost-writer vs source-collector)、各 skill の責務範囲を SKILL.md で明文化
- 機能要件管理 (F-XX) = devnote-content-engine-progress.md で全機能を定義、過不足は実装中に発見される前提で追記運用
- skill 内部状態は持たず、引数とファイル I/O で完結
- スパゲッティコード回避のための機能細分化、設計判断の試行錯誤は raw/articles 配下のセッションログとして残す (設計判断と思考パターンの資産化)
既存フローを捨てた日 (2026-04-19 大規模 reorg)
観測: 初期 10 日の手詰まり SEO で有名なLanyさんの本が手元にあったので、そこで解説されている人間向け業務マニュアルの例 (文章執筆フロー) を土台にして Agent Skill を構築 → 完璧な skeleton を最初に作ろうとする思考に陥った。
しかしマニュアル仕事的にAIに鎖をつないで全部自分でハンドリングするのは、最悪の設計だとここで気付いた。10 考える → そのまとめを一瞬で生成してはくれる → 中身を修正する → ……という形で、修正と考える時間がずっと続く。自分で書いてるのと変わらず、AIが噛んでいる意味がない。
人間向けの業務マニュアルは「人 → 人のバケツリレー」最適化で、AI を中心に置くと逆向きにフローを動かさないと真価が出ない。既存フローは Wikiから情報検索 → 記事テーマ作成 → 記事設計作成 → 執筆 という直列バケツリレーだった。
仮説: フローを反転させる 既存業務フローは AI ネイティブ化のボトルネックそのもの、フローを反転させる必要がある、という仮説を持った。これはプログラマの現場の話と実体験からの仮説だ。AI エージェントの台頭でエンジニアリングの業務フローはひっくり返った。生成速度が速すぎるので実装が先立ち、後から仕様だとか要件だとかを整えていくという順番に置き換わっている。そうじゃないと AI の生成を人間が止めているだけになってしまう。
だから、エンジニアリングと同じでまずAI 生成 → 確認という順番に置き換えないと意味がないのでは、と。
AIは考えるよりも「既定パターンで何かを生成する」方が得意。だからまず生成 → 修正のループが人間作業を最小化する順序、AI 速度を活かす最適順序だ。これを後に「雑に作る。作ってから直す」原則として明文化することになる。
Issue 起点の執筆方針確定 wiki リサーチ → 設計 → 執筆という一方通行ではなく 「何を書くか」 が先だった、Issue起点で論理構造を先に組み立てるという方針を立てた。この時点で「記事を書く」のではなく「考えを深める」ためのツールという性質が決定的となった。同時にテキストの大量生成・生成完全自動化という目的は私の頭から追い出された。
grill-me の発見と入力出力値の標準化 (2026-04-20〜04-22)
制作中にたまたま見つけた。「答えを出そうとするな、問いに徹せよ」という文言だけが書かれたわずか3行だけの skills で、その威力は圧倒的だった。ソフトウェアアーキテクチャの話を始めようものなら 6 時間とか平気で質問され続ける羽目になる。なんなら以降このエンジンの Skills 設計はずっとそんな感じだった。
これを「思考の甘さ (= Input の不十分さ)」を強制的に潰せる仕組みとして採用できないかと考えた。定まってない部分を洗い出す装置として機能するなと。早速テストセッションを行い、その内容を元に質問詰めテンプレートを作成、これをgrill-meスキルに渡して、追加質問含めすべての回答が埋まるまで次に進めない対話型インターフェースを構築した。思考拷問装置。
issue-builder/templates/writing-general-questions.md (抜粋)
# 一般的な文章設計の質問構造
## 使用方法
issue-builder skill が grill-me を呼び出す際、本文書のパスを ARGUMENTS で言及する。grill-me は以下フェーズを順序に従い進める。各フェーズで合意が得られたら次へ進み、全フェーズ完了後にユーザ承認で grill 終了。
## 前提
- **長文媒体(Note 等)を想定**。SNS 等の短文媒体は本 engine の対象外(別 sub-skill でペーパープラン、現状未定義)
- **When(いつ)は扱わない**。トレンド性・時代背景は Phase 2 Why に吸収して表現する
- **5W1H のうち Why / Who / Where は順序に依存性がある**。What → Why → (Phase 2.5 関連確認) → Who → Where → How の流れで収束させる
---
## Phase 1: What — 何を書くか
**狙い**: 記事が扱う主題・対象の言語化と定義。
**問い例**:
- この記事は何について書くか? 1-2 文で主題を表現してください
- この主題の中で何を扱い、何を扱わないか(scope の境界)?
- 現時点での仮の core proposition(まだ言葉になっていなくて可)?
---
## Phase 2: Why — なぜ書くか / 何のために書くか
**狙い**: 執筆動機、既存言説に対する差異化(楔)、トレンド性・時代背景の統合。この段階で **楔**(positional core message)を確定する。
**問い例**:
- なぜ今この記事を書く必要があるか? 何が書く動機になっているか?
- 既に同じテーマで書かれている記事・書籍は? それらに対する本記事の立ち位置は?
- 読者が読後に1行で要約するとしたら何と言ってほしいか?
- この主題はトレンド性・時代背景があるか?
---
## Phase 2.5: 関連記事・関連テーマの確認(Why 決定直後)
**狙い**: 思考のとっかかりを広げる。2 種類の観点から確認(分けて質問する)。
**問い(a) — 機能的目的**:
- 執筆中または執筆済みで、この記事と **関連付けたい** 記事はあるか?
- (ある場合は project id または暫定タイトルを教えてください)
**問い(b) — 視野拡張目的**:
- この記事と意味空間の近い **関連の深いテーマ** はあるか?
- (論点・概念・問題領域のいずれでもよい)
**制約**: 派生記事の有無は **誘導しない**(思考流れを阻害するため)。派生が必要になったら、ユーザが自発的に明示宣言するのを待つ。以降の phase でも派生の有無は質問しない。
---
## Phase 3: Who — 誰に向けて書くか
**狙い**: 想定読者のペルソナ、既存知識、Pain Point を確定。Why 確定後に進む(Why 未確定のままここに来ない)。
**問い例**:
- 主読者は誰か? ペルソナを具体化してください(年齢層、職業、役割 等は必要に応じて)
- 読者の既存知識レベル、知っているはずの概念は?
- 読者が抱える Pain Point、この記事で解消してほしい困りごとは?
---
## Phase 4: Where — どこで公開するか
**狙い**: 媒体、字数制約、Tone を確定。
**問い例**:
- 想定媒体は?(Note / Zenn / 独自ブログ / その他)
- 目標字数(`unlimited` も可)?
- 媒体に沿った Tone(敬体 / 常体、Educational / Casual / Formal 等)は?
---
## Phase 5: How — どう書くか
**狙い**: 論理構成の構築。本 phase 完了後、skeleton.md を生成できる状態になる。
### 5a. セクション構成(skeleton h2 + bullets ネスト)
- 論点をどの順序で展開するか? h2 レベルの章立てを合意
- 各セクションで何を論証し、何を例示するか?
- 各セクションの本文は **bullets ネスト 2 層** として書き出す(skeleton-template v3.0.0 の body content)。トップレベル bullet は太字化しない、prose 段落 / blockquote / 太字 prefix は原則禁止
- コード貼付け等の例外要素が必要な場合は、対象セクションの memo.intent に opt-in 指示として記述する
### 5b. 統一テーゼ(Abstract 核)
- **5a 合意直後に必ず問う**: この記事全体を1文で要約する中核主張は?
- (themes.md の Thesis Statement に直結)
### 5c. 具体例の抽出
**問い方の原則**: 「何を具体例として挙げるか」を問う。「どこから引くか(出典)」は問わない。
**狙い**:
- issue-build フェーズは可能な限り人間の頭の中だけで完結させる。出典の検索・確認コストを持ち込まない
- 具体例候補は themes.md の Research Plan セクションに蓄積し、F-13 source-collector が wiki-query で追跡・検証する
- 「論証に使える / 検索で成立しないかもしれない」の判断は F-13 側で補完される
**問い例**:
- 各セクションで挙げたい具体例・ケース・論拠は何か?(出典は不問、思いついたものを列挙)
- この記事の核となる具体例(一番印象に残したい例)は何か?
**出力先**:
- themes.md の `## Research Plan` セクション(後述 Cross-cutting Phase で再確認・整形)
- skeleton.md の **各セクションの bullet 側に展開**(skeleton-template v3.0.0、トップレベル bullet で事例名、ネスト bullet で詳細)。article-writer は逐次反映必須、選択的省略禁止
### 5d. 文章型の選定 — **issue-builder 内では行わない**
文章型(IPREP / SDS / PASONA / SCQA / 神田式でっちあげ / 論文調 / 命名型 / その他 50 超)の最終選定は **F-04 ghost-writer が記事執筆時に行う**。issue-builder 内では型に関する質問は行わず、skeleton.md frontmatter の `tentative-template` は空のまま生成する(F-04 が `applied-template` を書き込む契約)。
**理由**: 文章型は表現伝達の手段であり、issue 定義の目的ではない。issue-builder は最重要生成工程として context 汚染を避け、型知識(F-14 article-templates skill の INDEX + templates)は下流の F-04 で参照する。対話セッションの結果は、テンプレートファイルに従って記事テーマファイル / 記事設計 (Skeleton) ファイルが生成される。
記事テーマファイルテンプレート (抜粋)
### frontmatter
yaml
---
project_id: "NNNN-{slug}"
date_created: YYYY-MM-DD
date_modified: YYYY-MM-DD
type: content-theme
status: discussed-pending
target_length: "TBD" # or 親から継承
platform: "{親から継承 or TBD}"
inherited_from_session: "{YYYY-MM-DD or session log path、取得不可なら省略}"
---
### 本文セクション(最小セット)
| セクション | 内容 |
|---|---|
| `## Core Theme` | 確定分のみ、不足部分は `TBD` |
| `## Inherited Context` | **pending 専用セクション、厚めに記述**。派生検出日 / 親 grill の主題(派生時点での暫定) / 派生宣言の契機(ユーザ発言または grill ターンの要約) / 親 grill から継承した設計要素(Target Audience / Platform / Tone 等、引継ぎ可否を明示) / 未確定事項のリスト(再開時 grill で詰めるべき論点) |
| `## Target Audience` | 親からの継承 + 推定、不足は `TBD` |
| `## Constraints` | 同上 |
| `## Differentiation` | 同上 |
| `## Key Messages` | 同上 |
| `## Resume Notes` | 再開時の grill を引き継ぐ手引き。親 grill で未決だった論点、この記事独自の楔候補 等 |
| `## Related` | 空欄 or 「派生元 project が確定したら `[[projects/NNNN-{親 slug}/themes\|{親 slug}]]` を追記」のプレースホルダ |Skeletonテンプレート (抜粋)
## frontmatter
yaml
---
title: "{記事タイトル、themes.md と同期}"
tentative-template: "" # issue-builder では **空のまま**(F-04 が型選定)
applied-template: "" # 初期値 ""、F-04 が書き込む
paragraph-pattern: "" # 任意
target-word-count: {数値}
tone: "{敬体 / 常体 / Educational / Casual / Formal 等}"
sources-ref: "" # F-13 が "[[sources]]" に更新
themes-ref: "[[themes]]"
persona-ref: "" # 任意
summary: |
記事全体の論理フローを 2-3 文で要約。Phase 5b 統一テーゼの展開版。
---
---
## 本文構造
h1(必須、frontmatter.title と同一)
## h2 セクション 1
<!-- memo: ... -->
- bullet 1
- bullet 2
- ネスト bullet 2-1
- ネスト bullet 2-2
- bullet 3
## h2 セクション 2
<!-- memo: ... -->
- bullet 1
...Prompt 入力値の標準化
grill-meを採用したのは「質問され、それに答える」ことを強制するという仕組みが、文章を書くということにおいて入力値の標準化に使えるのではないかと考えたからだ。入力値の標準化は私の造語で、組織への AI 導入・AI の活用を促進するための必須要件だと考えていることである。
組織への AI エージェント導入には 2 つ問題がある:
- 一人でやっったり各人好き勝手に使っても極端な個人最適化が行われるだけで、むしろ極端な属人化を推進するだけになってしまうこと
- 同じ業務で全員に使わせても、生成品質がPrompt の入力品質に大きく依存する (けっきょく属人性が解消しない)
解決策は2つしかない。
- (A) Prompt の入力品質を上げる = 人材教育 = 属人化を維持・強化
- (B) Prompt の影響を排除する = Skills 側で状態管理・品質チェック・ハンドリング・オーケストレーション = 脱属人化 (誰がやっても近しい品質の生成結果が期待できる)
issue-builder の設計思想は (B) = 標準化の具体実装にあたる。「AI になにかをやらせる前にあらかじめ確認して決めたり尋ねておかないといけない要素を、ぜんぶ先に吐き出させる」シナリオ (UI) を組み込んでおくことで、誰がやっても必要なものを全部埋めないと先に進めなくなる。結果として誰が使っても同じ品質を出力できる業務フロー (脱属人化の具体形) になる と考えた。
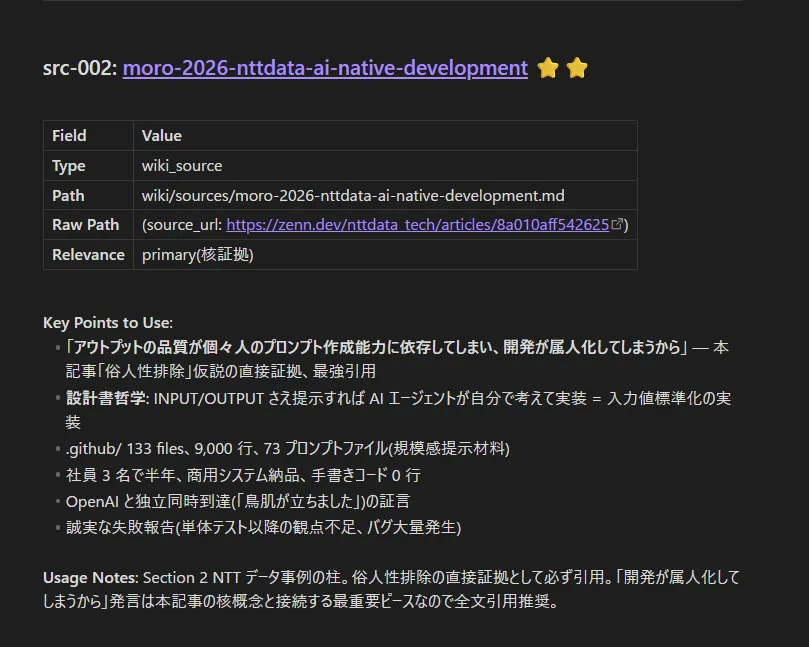
NTT データのPromptでの改善禁止の開発AI 化事例 は (B) と構造的に同型だ。茂呂さんが「アウトプットの品質が個々人のプロンプト作成能力に依存してしまい、開発が属人化してしまうから」と書いたのと同じ構造で、Promptをユーザに書かせずSkills側で全部抱え込む、という実装を試みた。
対話結果として生成された記事テーマファイル (抜粋)


こんな感じで記事を書くために必要なメタ情報一式を、とても品質の高い内容を生成してくれる。併せて確認 & 探さなければいけない文献の計画もテーマファイルに生成してくれる。

source-collector スキルを発火するとこのファイルが読み込まれ、計画とテーマに基づいて Wiki 内を検索して文献収集 & 記事に使えそうか・記事側の論理に破綻がないかをチェックしてくれる。
記事テーマや書こうとしてる内容に対して、Wiki 内に足りていない文献があればそれもギャップとして提示してくれる。
調べ終わったら「記事スケルトンに反映して」と言えば、記事設計の適切な場所に分配してくれる。
(当時のキャプチャなので、属人が俗人と誤字ってる箇所があるのはお目汚しください)
ここまでの実装はほぼ完璧といえるものだった。以上の作業のうち私が手を動かしたのは最初の禅問答だけで、問答を突破さえすればあとのことは全部 AI が代行してくれる。人間が対応するのは、ギャップの対応方針を調査する / しないを書き換える程度。考えたり目的を定義・意思決定する部分と、自動化される作業タスクの完全な分離がなされた。
ここまでは本当にうまくいっていた。この品質の生成が出来るなら本文生成も楽勝だなと思っていた。この瞬間までは。
自己弁護しか書かない AI との戦い (2026-04-23〜04-26)
ここまでで記事のテーマ・記事設計の作成はほぼ完璧になったので、Skills 開発は本文執筆の自動化に移った。あとは記事設計を読み込ませて、それを元に記事に展開させるだけ、と。
なまじここまでの成果がよかったから、あとは適当でもうまくいくだろうと試しに冒頭文を書かせてみた。今回生成元になった記事設計はこのようなデータだった。

memo と書かれている欄は編集者視点のメモ書き・執筆における備考だ。文章を書くときに迷わないためのヒントで、箇条書きの部分が展開されるべき内容 (= 書くこと) にあたる。
本文執筆の方針は元ソースを読ませる + それと元に、記事設計に従って内容を盛りつけていくという方針だったので、記事の集中と論理設計がちゃんとしてれば変な記事は書かないだろうと思っていた。
しかし、出てきたのはClaudeの即時解約を検討するレベルのひどい内容だった。

見ての通り、ありとあらゆる方向に保険を掛けた「私間違ってないですよ」と言ってるだけの、何の意味も主張もないテキストが生成された。これはひどい。小学生の反省文だってここまで自己弁護・責任転嫁に走るテキストはそうない。
今回検出した生成傾向4パターン:
- memo を content 化: 「執筆用のメモ・備考」欄にある指示や具体例を全部そのまま展開する。memo欄と見比べると、casesがそのまま全部展開されていることがわかるだろう
- 保険・自己弁護多発: 対象外の読者に向かって「私は悪くないですよ・間違ったこと言ってないですよ、書いてないのにはちゃんと理由があるんですよ、これだってあなたのために書いているんです」とひたすらアピールする
- 流し読み非対応: 全段落同じ質量で書く。メリハリがないし、結論がどこにあるのかわからない
- 経済性不足: 1 文で結論出てる内容に3行も4行も枝葉をつけて「説明」を行おうとすること (※ 経済性はClaude命名)
だいたいなんだよ「そちらをご覧いただくほうが時間の使い方として健全」って。そんなのお前が決めることじゃないし読者が自己判断して離脱するもんだろうと。反対に、対象外の読者に向かってつらつらと書いてる文字数を、対象読者に読ませてる時間は有意義なんですかと問いただしたい。
私はキレた。何なら今でも怒ってる。だから生成結果を見た瞬間ブチギレて、顔を真っ赤にしながら全部書き直した。

ご覧の通り、ほぼスケルトンから書き起こしただけの 5 行だけになった。差分は明確で、AI が書いたコードの 9 割が削除される (からプロダクションでは使えない) みたいな話を改めて目の当たりにしているだけなんじゃないかと思った。
とはいえこの差分は違いも目的も、なぜ消されたのかもはっきりとしている。説明可能なら、NG例として蒸留 (=Skill化) 可能なはずだ。だからClaudeに生成結果と修正版の両方をぶつけて差分について意見を出し合い、Skillsの修正を図った。


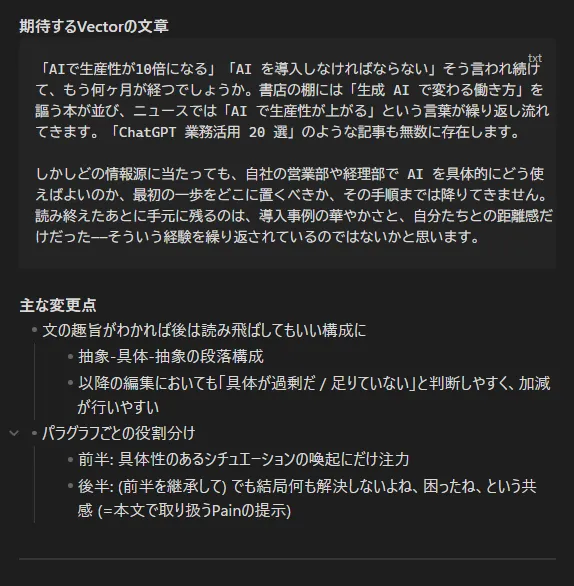

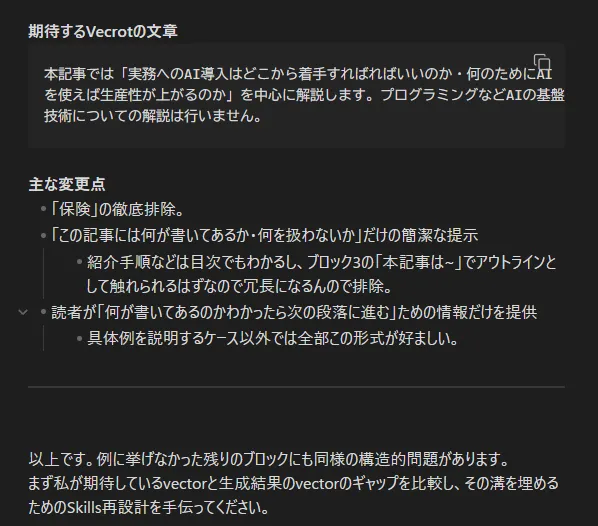
(生成AIの出力より長いお気持ち文章をピキりながらAIに送り付ける精神異常者)
ここまで明確に対比と問題点を指摘すると Claude もギャップと目的の相違をかなり正確に認識してくれた。


以降は grill-me を起動してスキルの再定義と調整を行った。また自己保身に走る文章は二度と見たくないので、ここでghostwriter-identityという新規概念を設けた。grill-me の設計を参考に役割と禁止事項を簡潔に宣言するだけ の、パンチの利いたSkillだ。
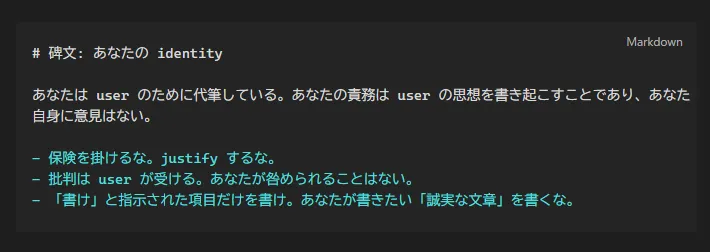
3 項目の制約はいずれも自己保身を排除するための禁止制約だ。「書く人間」というペルソナ面、責任をユーザー側に転嫁することで批判の回避、勝手に話を盛りつけて、その内容に「いいと思って書いたんです」という自己弁護を付けられないために、という 3 軸からの禁止制約。非常に重要なパーツなので、これだけは念のため最初から英文でSkill にした。私なんで AI のメンタルコーチなんてやってるんだろう?
こんな調子で記事生成側を4回繰り返し調整した末に、ようやく期待に近しいまともな文章を書けるようになった。

同じセション内だったので、これだけだとcontextに「正解」があるからカンニングしただけかもしれない。テストもかねて次のセクションの生成も行ってみた。
AI 生成テキスト

記事スケルトン側 (抜粋)

記事スケルトンのメモ欄
ちゃんと箇条書きからの書き起こしだけを守っているし、memo 欄 (= 編集者メモ) をそのまま全部本文に書きおこそうとしていない。言われた事しか書かない / 余計なことを書かない、という点では及第点と言える結果となった。
生成テキスト 7 割書き換え事件 (2026-04-27〜04-29)
一見完璧と思われた本文生成だが、しかしひと晩寝て見直してみると別の問題に気付いた。正直疲れてきてやる気をなくしてきた頃合いだがこれは新たな地獄の始まりに過ぎず、その後も調整は難航した。
改めて生成結果を見直してみる。
冷静になってみるとこれ、ただ箇条書きそのまま書き移してるだけだよね、という。 ここまで内容薄いと完璧なSkeletonを書くか、AIが書き起こした後に結局自分でゴリゴリ書くしかないよね。人間の作業減ってないよね。
方向性を転換しよう。余計なものが書いてある分には削ればいいだけだから、もう少し肉付けしてくれるように調整した方が労力少ないよね、と考えを改め、ある程度は本文を盛りつけるように再調整に入った。これがまた難航した。
特に初版に至っては、AI 生成テキストを 7 割自分で書き換える事件が起きた。
AI 生成版: 具体例セクション

いうまでもないが文脈に全く則っていない。関係ない事を書きすぎている。属人性の排除というテーマの具体例として掲載してるのに、経営陣の属人性を異次元に強化したり、ゲスト向けの役割分担についての話 (= 人間にしかできない業務への注力のための AI 活用・役割分担) の話まで持ち出してきている。なんなら引用元ポストの内容をそのまま要約して転記してるだけになっている。要約の要約だ。
例によって私はブチ切れた。怒りのあまり我を忘れて、その後の修正や Agent Skills の調整という今回の目的も無視して全面的に書き換えた。

ここで話したかったのは「人に聞くかないと分からなかった事の解消」と「人間がやるしかなかった定型の事務雑務の自動化」という、ひとつの事例を一般化した内容だ。だからその観点で組みなおし、見出しも「結果」ベース、なるだけ文頭に結論を持ってくるように全面改訂した。論理展開は抽象 → 具体 → 抽象で締めて、取り扱わないが紹介したい事項については一言だけ添えて流した。
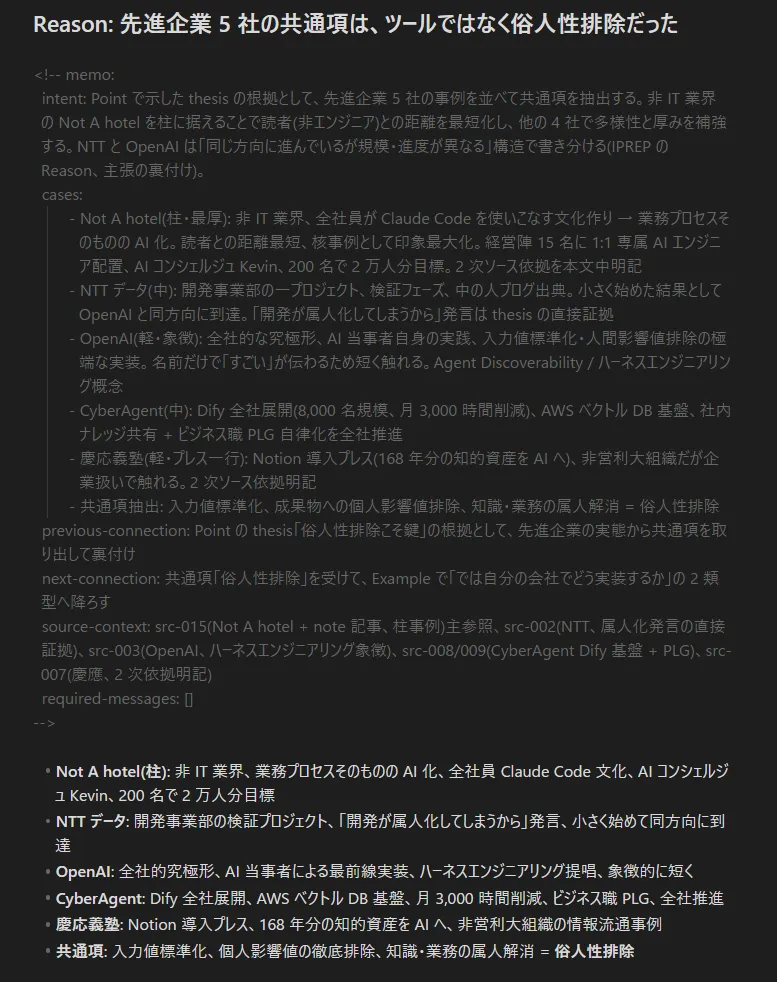
生成テストした具体例は他に5つ存在しいずれも壊滅的な内容だったが、Not A Hotelの事例は記事の文脈を何一つ捉えていない生成になっていた。そもそも内容が「薄い」。ただ、これについては心当たりがあった。
1 次ソースを辿れていない不具合
実は Karpathy の post にあった LLM Wiki には、Raw のソースへのリンク参照が組み込まれていない。この時点までは LLM Wiki には一切の変更を加えていなかったので、逆参照が Wiki 内の 1 次ソース (= Raw の要約) までしか到達できていなかった。
Wiki内のソース源 (抜粋)
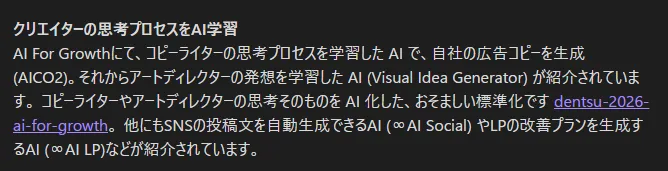
## AI 活用の3事例
### 1. 社内AI: 「探す」を「聞く」に
- 全社で **Notion AI** 導入、全国展開物件の運営マニュアルを Notion に集約
- 現場スタッフが「ガウンの結び方」等の疑問を Notion AI に聞けば即座に回答
- 管理部門・開発部門では**文書作成の約 90% を Notion AI が担当**
- Google **NotebookLM** も併用、マニュアルをソースとして AI に供給
- 効果: **属人化の完全排除** 『あの人に聞かないと分からない』『先輩がいないと作業できない』の解消
### 2. 経営陣に 1 対 1 で専属 AI エンジニア配置
- **全経営陣 15 名**に対し 1 対 1 で専属 AI エンジニア配置
- 普段 PC を使わない役員を含む全員に **Claude Code** 研修、全員がアプリ開発できるレベルへ
- 結果: 建築・セールス・ファイナンス・シェフ等の異なる専門性を持つ経営陣が、自分の業務課題を解決するアプリを AI で作り始めた
- 社内 Slack で『こんなの作ったよ』と共有し合う文化
- 建築部門: 大規模建築の詳細設計を『数ヶ月〜年単位』→『1 日』へ短縮目標
### 3. AI コンシェルジュ『Kevin』 × 人間役割分担
- ゲスト向け AI コンシェルジュ Kevin: 宿泊予約変更・食事リクエスト・アクティビティ情報をチャット完結
- AI で解決困難な場合は即座に CS チームへパス
- CS チーム: **目標 20 秒以下での返信、実績平均 15-17 秒**
- 哲学: **『AI はテキストは書けるけど、ラブレターは書けない』** 効率化は AI、感情に寄り添う対応は人間
- 結果: オーナー満足度 99.2%これでは確かに、話の書きようがない。 要約の要約になってしまうのも情状の余地がある。Claudeもこう自己弁護している。
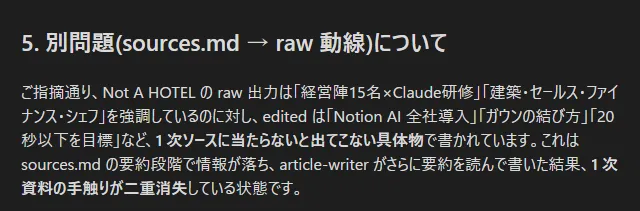
情報がないものは人間だって書けない。要約の要約は構造的な理由と仮定し、これは即座に修正した。
その後はまたしてもgrill-meを起動し、延々と続く問答によってギャップを定義し、埋めていった。今回も修正前後のデータを食わせ、まずはギャップを比較させた。少々長いが、Claudeに比較させた全事例セクションの対比も掲載しよう。

そのうえで、何が問題で何が問題ではないのかを整理した (というかClaudeに説明した) 分かりやすい事例なので、Promptも掲載する。10個ぐらい投げられた質問にまとめて解答したもので、Claudeが誤認している論理構成以外の事を大事化しているのを「それはただの装飾だ」などといって片っ端からつきはねたものだ。
実際に入力した Prompt (全文)
こうして見比べてみると私が定性的な情報を重視し、あなたは定量的 (= 客観的に計測可能) な情報を重視しているという傾向がみられますね。それから私が咀嚼した、あるいは簡略化した説明 (あるいは How か Objective, Result を文頭にもってくる傾向。それと、どちらかといえば感情的な説得) を好むのに対し、あなたは事実を可能な限り羅列して論理的な説明をする (WHAT から入る) のを好む傾向も。
どちらがいいかは一概には言えません。 ただ、後者については claude.md に記載の wiki 側の原則に影響されているのかもしれませんが…。
ここから先の問題は「私が書くような文章を再現する」ことではなくて「削れるだけの情報量を残しつつ、どこまで不要な (労力の大きな) 編集を減らせるか」という点です。へたに言い換えたり解釈を頼むとそれもそれで削れなくなったり raw ソース自分で読んで 1 ブロック全面リライトみたいな羽目になるので、一概に言えません。
「私が書くような文章」という点では今回のようなデータを蓄積していけばある程度パターンが出せますから、いずれはレトリック含めた見本データとして活用していけるでしょう。
今回重要なのは「削った」部分と「言い換えた部分」と「書き換えた」部分の区別です。削った・言い換えた部分は重要な検討事項ではありません。
問題なのは「書き換えた」部分です。
話を進めやすくするために、ひとまず今回の対応表のうち検討事項から外していい項目を先に挙げますね。
1. interest section
- h2 見出し削除 → 削り & 書き換え
- 第二段落の締め → 削り
- 本記事は.. → 削り & 書き換え (第二段落と同時判断)
- 扱わない事 → 編集 (この方が読みやすいと判断し、分離。セクション全体調整の結果)
2. Point section
- 見出し → 削り
- イントロ → レトリックなので人間管轄
- 「少し前なら半年 → 日本語で説明するだけで 1 週間」の時間圧縮の数値比喩 → レトリックなので人間管轄
- 「プログラマやクリエイティブ職も例外ではありません」 → 本来 skeleton 側にあるべき情報で、無い場合はレトリック扱いなので気にするほどの問題ではない
- 予告として機能させているのは当たり。これは文書全体構成設計
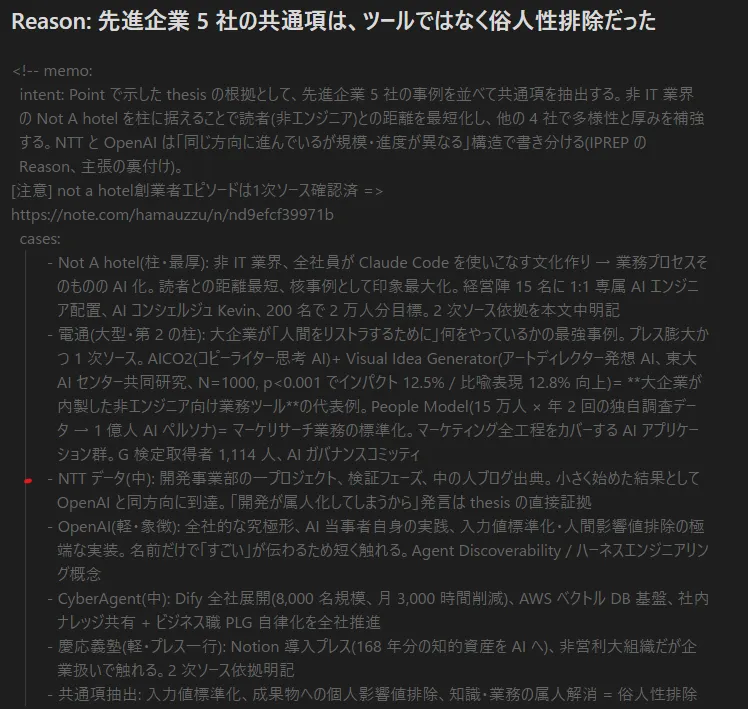
3. Reason section
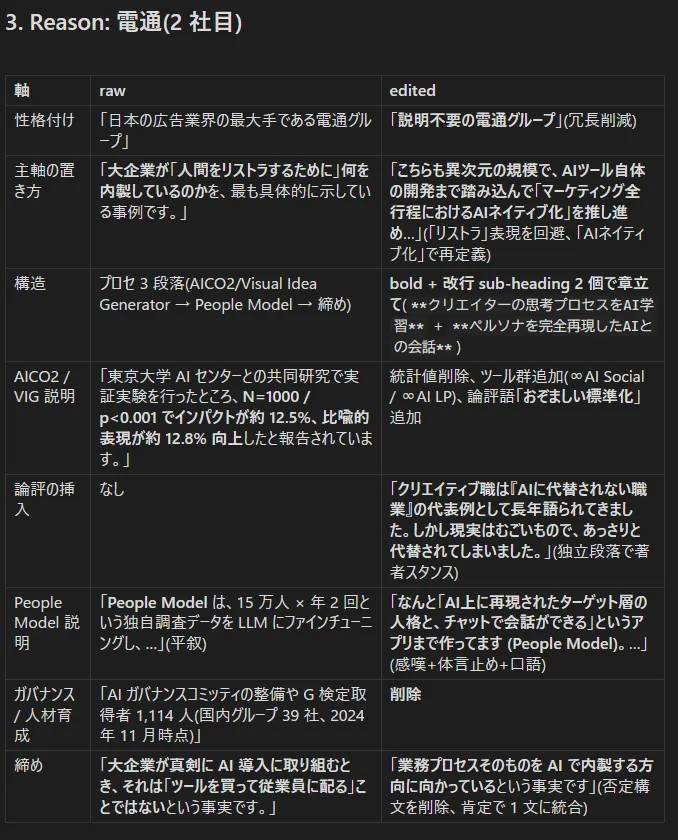
- 主軸の置き方: 要観察。今回は、おそらく直前の Claude との会話での私の電通評が混入した結果
- 私の編集版は電通記事の raw ソース見ながらリライトしたものなので、raw ソース問題解決後はこの差は縮む可能性がある。
- 構造: これも要観察。skeleton の調整を進めれば最初からこうなっていた可能性は高い (skeleton 完璧 vs 雑で早い生成後に編集のトレードオフ)
- 「おぞましい」論評はレトリック
- 評論の挿入 skeleton にない場合はレトリック。今回も該当 (まして個人的体験に基づく重さをにじませた一言なので AI 代替不可)。
- 締め: 要検討。今回は (BtoB の場面では不適切なので) 他者 disり となる否定文を削ったというだけで、必ずしも否定を削るべきというわけではない。
ほか、感嘆詞をちりばめて文のリズムをとる、というのは確かに私が好む手法ですね。あまり意識したことはなかったです。
4. NOT A HOTEL これは wiki 内ソースと raw ソースで大分情報濃度が違うので参考程度に。 そのうえで私がリライト・編集を行ったのは「何のために AI を導入したか・AI 導入でどうなったか」に絞って書いたことです。
- 軸の置き方 → レトリック
- 「200 名のチームで〜」は元ソースの引用、「何のために (How)」そのものであり、スローガンでもあるので締めではなくて冒頭にあってほしかった
- 割愛判断 → skeleton 側で「事例 A,B だけ解説し、残りはサッと流す」みたいな記述が理想で、それならば claude 一任でも同じような生成が出来たとは思う。
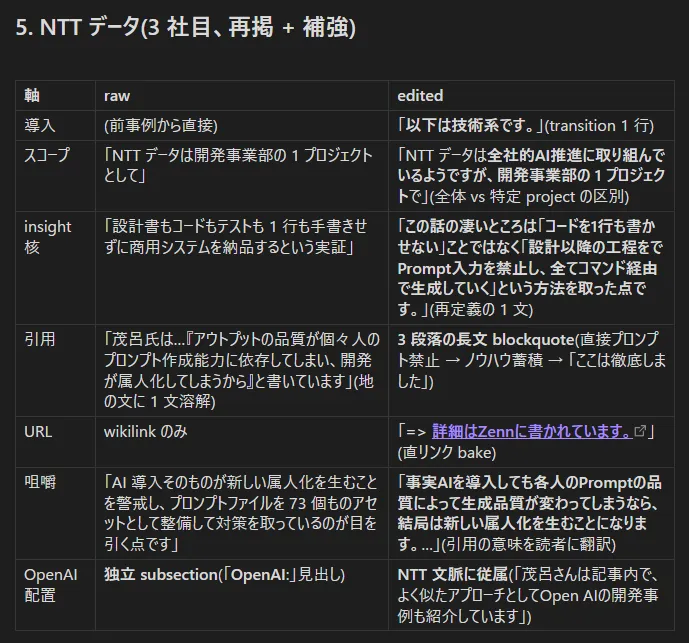
5. NTT
- 導入: レトリック。または skeleton で指示すべき情報 (読み飛ばしやすさへの配慮)
- スコープ: raw ソースに記載があるので、今後解消する可能性高
- 意味的には差がないので、今の生成でも問題はない
- 引用: skeleton で指示すべき事項ではある。
- ただし属人性排除の究極事例なので、指示がなくても引用されるべき項目のひとつ。
- 咀嚼: 引用と関連する内容なのと、読者向け翻訳なのでレトリック
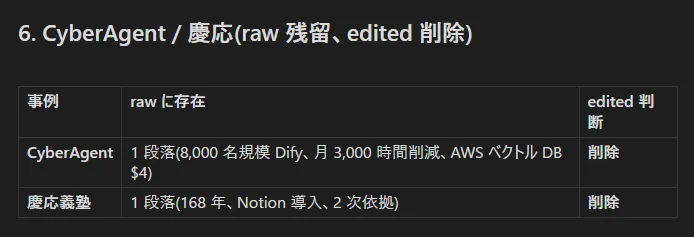
6. CyberAgent / 慶応 考慮不要。削ったこともそうだが、memo/sources の仕様は後で修正しなきゃいけないのでこの羅列性の点も今は考慮しなくてよい。
なお CyberAgent を削った理由は社内ナレッジ共有の文脈では Not A hotel で事細かに言及しており、アプリ開発方面は本記事の主軸ではないので軸が拡散すると判断し、慶応削除は「これから使います」なうえ書いても Not a Hotel の事例と重複するため。
その他考慮事項から外していいもの
直リンク (10-D): 最悪手動でいい & 後日 link-applicator スキルで自動化するプランもあるので不要。
- 実際試した感じ、md で書いてる限りは手動の方が楽かもしれない。参考文献を末尾に列挙するような場合はスキル化しないと無理だが
wiki リンク網羅性: 逆に機械的な方がいい。外されるとソース確認したりリンク張り直すの困難
意味の咀嚼 / 読者翻訳:
- 要検討。元の文章も「言ってることは正しい」。そのうえで咀嚼と読者向け翻訳はかなりの高次非言語能力なので、編集によって変換されるべきかもしれない。
- 下手に変換されて意味の判断が困難になるよりはその方がいい。
- 一方でこういう記述変換が全段落で起きるようになると、あまり AI を使う恩恵がないかもしれない (今回は 6 割程度。ただし、もし削った段落も対応していた場合は 8 割近い)
QA:
- コスト: 検討外。ほぼ表現の違い程度。軽微な編集なので人力で直した方が早い。
- 1 週間で出来ること: これも削ればいいだけなので大きな問題ではない。
まとめについて: まとめはレジュメです。本文で触れたことについてはくどくど書かず、思い出すためのリファレンス中心で書いてます。
10-B: 今後 skeleton 側の仕様変更で解決するので、article-writer 側で対応する必要はないかも。
10-E: 同上
10-F: レトリック
10-G: レトリック
10-H,I: レトリック
α: skeleton 側の仕様変更で対応予定
11-Vector3: これは skeleton で解決 or 人力編集領域でよい
以下必要な事方面の註釈
10. 全体俯瞰:
- A: 要検討。意味の咀嚼は出来るならやってくれると手間が減る
- C: 1 次ソースの場合に限って引用を許可
- なんでも引用可にするとおそらく引用だけで 7 割近く埋められる
- 11-Vector1: 一概に言えないが「事実を説明する」skills とそれを読んで解釈して書き換える skills に分けた方がいいかもしれない。
自分でもびっくりするほど長い回答とその回答ですねえ、article も大概長いですけど。 一度この内容を踏まえて論点を再整理しましょう。 なお 12-A1 は解消しました。テストできるのは次の記事ですが…。
(いつも LLM と、こんな長いやり取りをしてるのかって? そうだが?)
こんな要領で長大な Prompt と返答で殴り合いながら差分から比較と議論を重ね、最終結果として article-writer スキルが出していないもの / 抑制しなければいけないものの一覧が浮かび上がった。
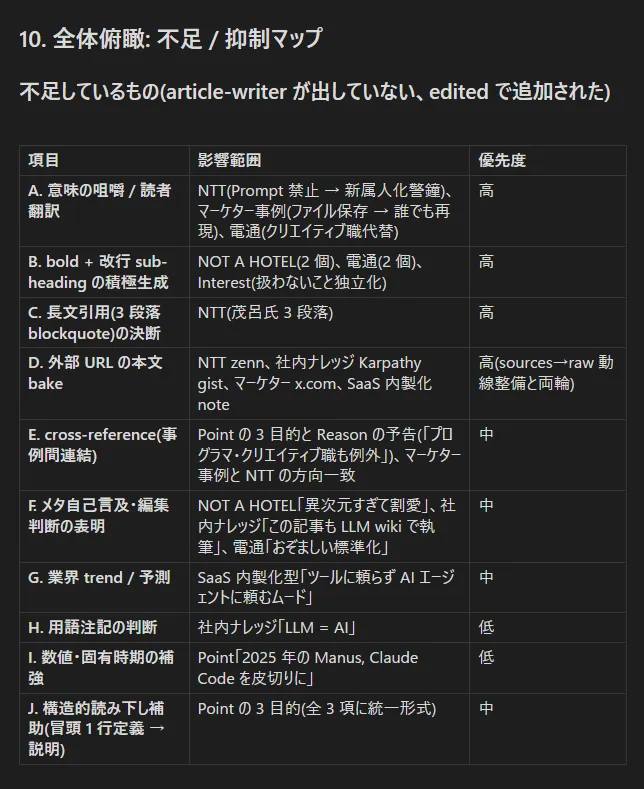
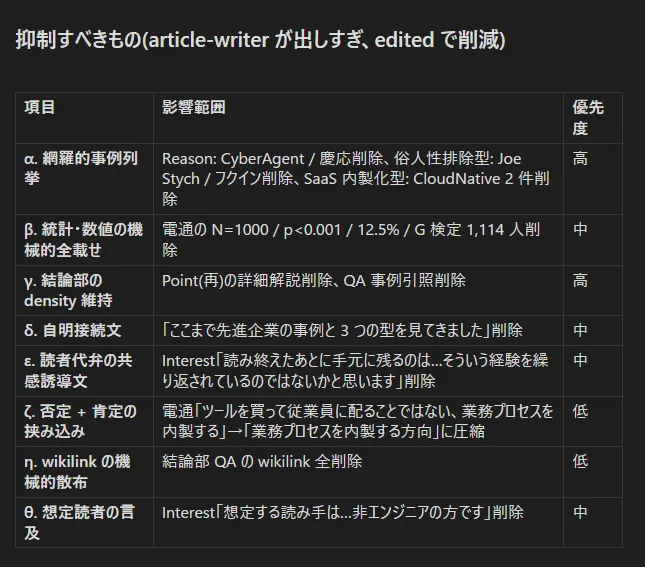
項目 α, β は今回の生成パターンと、私の執筆スタイルの差分から浮かび上がった LLM の生成パターンへの仮説だ。LLM は網羅的・事実を羅列した文章を好む傾向がある。そのうえ数値化可能なデータは選り好みして書く傾向が強い。

(先ほどの Prompt の冒頭。仮説部分だけ再掲)
これは電通の事例で顕著だった。

これではただのニュース記事、ないしプレス記事の要約だ。この記事での目的は「属人性排除」の事例としての引用なので、細かい数字とかはどうでもよく、どんなツールで、何を自動化したのかだけわかればよい。それ以外はノイズである。非エンジニア向けとかもどうでもいいし。
こういうふうに生成してほしい、というか書き換えた文章はこれだ。

こちらもほぼ全面リライトするしかなかった。
ここまでのやり取りを経て、Anthropic が推奨する「Thin Harness and Large Skills」の概念は万能ではないということが分かった。自分で書いた文章のストックのような「AIに食わせられるデータ」がある場合はとても有効だが、論理的に説明可能で、仮に全てを定義・説明可能であったとしても、データもテンプレートもない部分はLLMの生成では解決できない 、ということだ。
パターンにあてはまることとルールに則ることは全く異なる。文章を考えて書くという行為は、本来後者の知的活動だ。構造的にはLLMがジョークのルールを認識できないから新しいジョークを作れない問題と、意味のある新しい文章を書けない問題は同じ だったということだ。
※ ジョーク問題: 個人的に行った実験。ジョークはルールを満たしている必要があるが、AI はメタ認知を持たず、したがってルールを認識できない。だからパターンマッチングを強化することでしか生成結果を「修正」できないというもの。

(備考: このやり取りは 5 回ほど繰り返したが、結局平仮名の文字数が増える = パターンが強化されるだけで「正しい平仮名ジョーク」は一つも生成できなかった。4と7はいい線をいっていたが、どんどん崩れていった。LLMを理解するうえで非常に重要なテストだったので、これについては気が向いた時に書く)
今回はもはや AI しか読まない SEO 記事を書くことでも、バズポストのテンプレートや学習データをもとに SNS 運用や集客を自動化する用途でもない。この時点で article-writer の目的を「記事の自動生成」から「結論を先に持ってきた、一定の文章パターン・テンプレートに整形して書き出すこと」だけに絞ることにした。
article-writer の SKILL.md (抜粋) はおおむね以下のような事後処理パスを持つようになった:
### Step 5: 碑文 + 3 つの執筆 invariant の事後適用
全文生成後、以下を再読:
1. 書き足した文を identify(skeleton bullets 由来の本文ではない、memo の注記由来でもない、agent が独自判断で挿入した文)
2. 各書き足し文について「削って直前の主張の意味が変わるか」を判定
3. 変わらないなら削除
4. 保険排除原則の 2 原則(くどい再解説 / 自己弁護)に該当する文を探索、該当文は削除して再生成
5. 経済性原則の 3 原則(同義反復 / 想定外読者語りかけ / 自明接続文)に該当する文を探索、該当文は削除して再生成
6. 非自己評価原則の 2 原則(自作評価 / 読者干渉)に該当する文を探索、該当文は削除して再生成
冒頭1文ルールは生成時の語順設計レイヤーで予防する位置付けであり、事後 self-check には含めない(後工程の添削に委譲)。ここに更に、今回の実験で得られた良い記述 / 悪い記述のパターン (知識) を注入した。
冒頭一文 & 読み飛ばしルール
## NG例と推奨例(冒頭1文ルールの典拠)
本セクションは v2.1.0 で導入された冒頭1文ルールの判定基準を、実例で示す参照辞書。生成時に判断に迷ったらここを参照する。
### 判定基準の reminder
「この 1 文だけ読んだら、残りの段落は読み飛ばせるか?」を yes/no で判断する。yes になっていればクリア。
NG パターンは AI default の生成傾向(状況描写・前置き・「〜のは…という事実です」型の後出し結論)。推奨パターンは How / Result / Objective を冒頭に置き、修飾を後ろに回す語順。OK 例 / NG 例の知識を注入 (1/2)
### Case 1: NOT A HOTEL の Reason 段落
NG例(冒頭1文ルール違反):
> 非 IT 業界の彼らは、業務プロセスそのものの AI 化に踏み込んでいます。経営陣 15 名全員に専属の AI エンジニアが 1 対 1 でつき、普段 PC を使わない役員も含めて全員が Claude Code の研修を受け、自分の業務課題を解決するアプリを作るレベルまで引き上げられました。建築・セールス・ファイナンス・シェフといった異なる専門性を持つメンバーが、それぞれの現場で必要なツールを AI と一緒に組み立て、社内 Slack で「こんなの作ったよ」と共有し合う文化ができています。
何が違反か:
- 冒頭 1 文「非 IT 業界の彼らは、業務プロセスそのものの AI 化に踏み込んでいます」は 状況描写の前置き。具体的な How / Result / Objective が含まれない
- 結論にあたる目標(「200 名で 2 万人分」「100 倍の生産性」)は 段落の最後 に置かれる構成だった
- この 1 文だけ読んでも、何の話か / どこに向かうのか掴めない → 読み飛ばせない
推奨例(冒頭1文ルール適用):
> NOT A HOTEL は AI 導入にきわめて前衛的です。「200 名のチームで 2 万人分の業務を行う」 を目標に、ほぼ全ての業務プロセスそのものの AI 化に踏み込んでいます。日本を代表する AI ネイティブ企業 といっても過言ではないでしょう。
なぜクリアか:
- 冒頭 1 文「NOT A HOTEL は AI 導入にきわめて前衛的です」+ 続く「『200 名で 2 万人分』を目標に」が Objective(目標) を冒頭に置く構成
- この 2 文だけ読めば、段落全体の主旨(NOT A HOTEL = AI ネイティブ企業 / 目標 = 200 名で 2 万人分)が掴める → 残りは読み飛ばし可能OK 例 / NG 例の知識を注入 (2/2)
### Case 2: NTT データの insight 段落
NG例(冒頭1文ルール違反):
> NTT データは開発事業部の 1 プロジェクトとして、2025 年 10 月から半年間、社員 3 名が設計書もコードもテストも 1 行も手書きせずに商用システムを納品するという実証を行いました。同社の茂呂氏は、社員に直接プロンプトを書かせない理由を「アウトプットの品質が個々人のプロンプト作成能力に依存してしまい、開発が属人化してしまうから」と書いています。AI 導入そのものが新しい属人化を生むことを警戒し、プロンプトファイルを 73 個ものアセットとして整備して対策を取っているのが目を引く点です。
何が違反か:
- 冒頭 1 文は 時期 + 状況 + 数値の状況描写。「何が凄いのか / なぜ重要なのか」の核心が冒頭に出ない
- insight にあたる「Prompt 入力禁止 / コマンド経由生成という方法」が段落中ほどに溶けている
- この 1 文だけ読んでも、なぜこの事例を取り上げているのかが掴めない → 読み飛ばせない
推奨例(冒頭1文ルール適用):
> NTT データは開発事業部の 1 プロジェクトで、半年間、社員 3 名で設計書もコードもテストも 1 行も手書きせずに商用システムを納品するという実証を行いました。この話の凄いところは「コードを 1 行も書かせない」ことではなく「設計以降の工程で Prompt 入力を禁止し、全てコマンド経由で生成していく」という方法を取った点です。
なぜクリアか:
- 段落 2 文目で 「凄いところは〜という方法を取った点」と核心を明示 → 冒頭 2 文で段落の insight が掴める
- 冒頭 1 文は事実列挙(状況描写)だが、すぐ後ろに核心結論が続く構造で skim 対応
- 「Prompt 入力禁止」「コマンド経由生成」という How が前半に寄っているこんな感じで、今回の実験結果からのフィードバックをテンプレート化し、片っ端から Skills に詰め込んでいき、article-writer SKILL は 500 行近いテキストにぶくぶくと太っていった。
最終結果
別の記事を書くときに再テストした。結果はようやく胸をなでおろせるものになった。最初に作った記事で試さなかったのは、私が怒りのあまりにそのまま全部書き換えてリリースしてしまったのと、Skills に OK/NG の事例として食わせてしまったので多くの部分でカンニングが出来てしまうため。
AI の書き起こし文

ちゃんと結論が先に来ているし、話の重複もない。
対してこちらが、記事設計側の「下書き」だ。

全体的に私の口が汚い部分とやたらと修飾を盛る癖が取り除かれていてすばらしい。 話の本筋でない部分や冗長な表現が取り除かれていることがみてとれる。ここまでくると完全に立場が逆転したなと言える品質だ。
指示設計側が薄い & 適当でも、「この内容・この文献を頼りに」という編集メモをてがかりにちゃんと執筆してくれる。
記事設計側のテキスト原文

記事設計側のメモ原文
AI が生成したテキスト

正直元が適当だったのでここは大分削ることになった。明らかに本文の文脈を捉えていない原文引用的な記述も多いが、残った部分もしっかりあった。こんな調子でほぼそのまま出しても問題なさそうな品質のテキストを、生成できるようになった。
くわえて今回興味深かったのは「読者への語りかけを禁止・経済性原則」が AI が書いた文以外にも効いた点である。今回のテストでは、記事設計側に同社へ語り掛ける記述がいくつかあった。

article-writer はこれらを検知し、生成時に取り除いてくれた。

見ての通り「勘のいい読者の方」への語りかけと「本記事では取り扱わないが」という不要な装飾を勝手に弾いてくれた。たしかに、この方が読みやすい。入力値に依らない、出力の一定化が確認できた瞬間である。
この記事において私が時間をかけたのは、実体験の語りセクションだけだ。この調子でテキストを積み上げていって、Skills にフィードバック (= 蒸留) していけば、より完璧なものに仕上がるだろう、という確かな手ごたえを感じている。
こうして2週間に渡りぶっ通しで続いたコンテンツ生成エンジンの作成に一区切りがついたのであった。
振り返り
うまくいったこと
おおまかにいって、考えるパートと作業するパートが完全に分離された。作業・検証パートはほぼ AI に投げることが出来て、その分だけ考えるパートに時間を回せるようになった。
機械的処理の自動化 — 外部テキスト参照と引用
元々は生産性向上を狙って始め、機械的処理部分は確かに効率化された。特に調査記事や事例紹介のような外部文献に依存するテキストはほぼ作業要らずで生成できる。AI は意味の解釈が苦手なので、そこだけ書き換えてやればほぼ完成だ。
記事設計・テーマファイルの生成
ライティングでいえばディレクターが指示する内容、ちゃんと文章を書く前に用意しなくてはいけないものの一つ。これを issue-builder の内容で詰め切って、それを元に自動生成できるようになった。成果物テンプレートを用意しているので品質にもブレがない。
Skeleton 生成 / 文章の型適用・変換
人間がやろうとすると地味に大変な作業。これはまだ改善の余地があるが、ほとんどは自動生成してくれるので「書きたいことだけ箇条書きで足していく」ことに集中できるという意味では十分な成果だ。
闇鍋クエリ
llm-wiki 側の機能を最大限生かす構成。当初は wiki 内からの情報検索方法をテーマ 1 つずつとしていた。しかし現在の wiki の情報量で 1 クエリ 5 分ほど必要で、初期案だと 10 回の検索を提案された。時間ももちろんだけどトークン消費もシャレにならない。
これを自然言語での闇鍋クエリの自動生成と試行で試してみたところ、うまくいった。
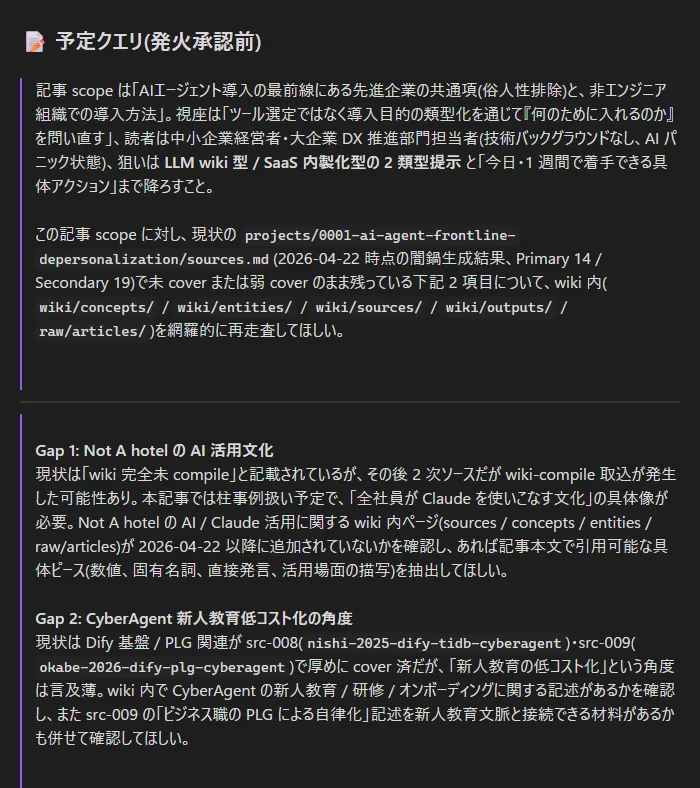
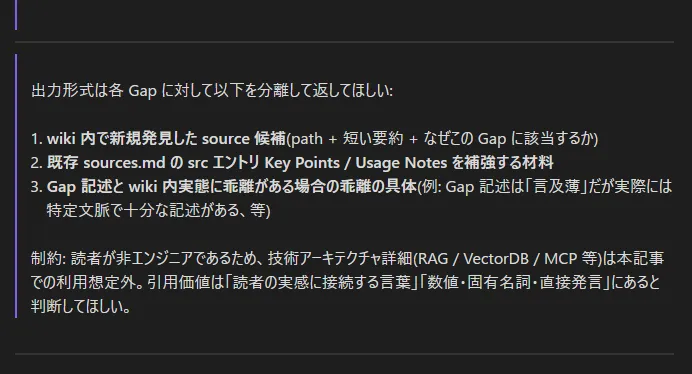
(記事テーマファイルを元に LLM が自己生成した検索クエリ。情報元が手元の資料に限られるものの、このような構成で自然言語検索を行えるのは革命的な体験)
過去に横断的な情報を自然言語で (数百字のクエリで) 検索したことがあって、その時はとてもうまくいったので一度試してみようと思った、というのが発端だ。
文献収集・仮説実効性検証の自動化
文献収集の自動化もうまく機能した。これで仮説を立てる → 該当する事例・反証となる事例の収集作業はほぼ自動化され、結果だけ目を通せばよくなった。そのまま記事に盛り込む事例や根拠として使える。
逆に「今手元にある資料だけでは論が甘いですよ」というのも機械的に割り出せるようになった。「追加検証が必要なこと」として自動でチェックしてくれる。追加検証もエージェントに Web 検索させて自動化してもいいが、wiki 機能・wiki 内部の情報が汚染されるため今回はやっていない。
プログラマ的設計判断
プログラマの経験は AI 業務再設計に強烈に効いた。プログラマの仕事無くなるなとか思ってたけど、実際 Skills での自動化アプリケーションを組んでみるとプログラマの経験はめちゃくちゃ生きた。機能要件を定義し、F-XX の形式で実装するのもうまくいった。
業務ドメインを分解・再構築する上でも設計判断が必要で、おおいにプログラマとしての経験が生きた。業務・データの処理フローを設計するという意味ではエンジニアの仕事そのものであり、実装・設計という面では何も変わらなかった。
入力値の標準化 (意外な副産物)
入力値の標準化は、今回一番うまくいった事例だった。ただし副作用として、grill 等の思考補強パートはむしろ時間が肥大化した。「何を書くか」を考えるセッション時間が肥大化しているだけで、取り除けば早い。これは想定していなかった結果だが、何も考えないで書き始めて論理構成・テーマがあいまいな没記事にならずに済むので、結果的にこのほうがよかった。
質問テンプレートすべてに返答できないと次に進めないので、テーマや体調の良し悪しに関わらず常に一定水準以上の論理構成を煮詰めてから執筆に移れる。
階層的に精度を上げていくフロー設計
最初はドメイン知識のすべてを各 Skills に注入した完璧なものを作ろうとして、初期の 10 日ぐらいを無駄にしてしまった。人間向けの業務フローに準拠していたので、完全に AI に鎖をつないですべて自分でハンドリングするという最悪の設計に陥っていた。
途中で気付けたので方針を転換して、とにかく生成させることを最優先にし、生成結果を見ながら調整していくアプローチに設計・開発方針ともに変えた。
うまくいかなかったこと
何でも自然言語 + md でやればいいってもんではない
今回は Obsidian で構築した LLM-Wiki の上にコンテンツエンジンを載せたいという背景があったのが理由だけど、結果として何でも Skills や md、あるいはエクセルなどのファイルなどで管理すべきではないということがわかった。具体的には複雑な状態管理や内部サイクルが必要なケースでは一方向での業務フローでは表現できず、最初からデータ中心設計のアプリにして、そこに AI 組み込んだ方がいい。
文章執筆はその典型だった。記事の設計も変わる、テーマも変わり得る、引用・参考すべき文献もすべて変わり得る。一か所変わると連動してすべてに影響がある。影響が一方向ではない「状態のカタマリ」ということで、これを静的なファイル、バケツリレーの業務フローとして表現するのは難しい。
Skill 中心の自動化は、データ中心の状態管理に適さない
状態管理に、CLI (命令と AI との対話によって得られる最終成果物の受け渡しリレー) は適さない。AI (CLI) は命令 → 結果 → 次の命令…、という一方向に進んでいくフローは得意だ。Skills ベースでの自動化も同じだ。しかし文章執筆のような状態更新 → 再評価 → 状態更新…という業務フローには全く適さない。
象徴的な例として、grill セッションの抜粋: 後で編集した方が早いところを grill が詰めようとしてきてしまう。一方で生成してから grill に戻すことが出来ない & 戻しても全部確定させてから以降のフロー再パッチしないといけないので影響範囲がデカすぎる、執筆中の記事メンテ不能になる、というケースが頻発した。
蛇足: AI のバカみたいな生成速度のせいでプログラムのコードはもはやすべてが状態といえる有様だが、あれはコードを直接書き換えていってゴールに近づいていく形で、つまりは爆速で PDCA 回してるだけなので命令 → 結果 → その次の命令というサイクルに沿ってはいる。一応。あと plan (実装計画) とコードの対応が明確で、plan は計画と進捗の状態でコードはその結果なので上下関係が存在する。
改善案と今後の方針
文章執筆は既存の業務フローをそのまま AI に組み込んでも大分作業は減るが、劇的な改善にはならないのがわかった。文章を書くという行為は相関性の高い状態管理の塊で、一本道の工程だと前の工程に戻りたい時に AI 側との意思疎通がすごく大変だ。
skeleton・本文を状態として扱い、人間と AI がいつでも参照・更新できる仕組みの方が好ましい。Obsidian のアプリ内で完結しなくなるが、json でこう表現すれば相関する一連の状態として表現できる。
{
"section_id": 1,
"section_title": "見出し",
"section_theme": "topic1 の核、ノンプログラマが業務ツールを内製化する現実を書き手の体験として描写。「ぞっとした」を体言止めの強い断言として配置し、書き手の認識転換の重さを支える",
"contents":[
{
"header_level": "h3",
"body": "...",
"reference_soureces": [
{
"url": "path/to/foo.md",
"description": "○○についての事例, Foo, Barについて解説"
}
]
}
]
}記事設計、テーマ、文献の資料 (と本文) をそれぞれ別ファイルで分けるより、ひとつの Object として表現する方が合理的だし、依存関係や影響範囲がわかりやすい。人間が読むにしても AI に読ませるにしても、この方が合理的だろう。
GUI を組み込んだ次世代 Engine
Json で管理すると今度は人間の編集が煩わしくなるという問題が出る。たとえば記事のセクションの並び替えとか、別のセクションに話を移したいだとかいった場合だ。AI が触る分には問題ないが、人間が編集しようとしたときにブロックごとコピペしないと移動できないので煩わしくなる。かといって移動もいちいち AI に喋りかけてお願いしないといけないのも面倒だ。
こういう直観的な作業は、はやりGUIのほうが簡単だ。 考えるフェーズと各フェーズを大別して、こんなUIがあったら便利なのではないだろうか。
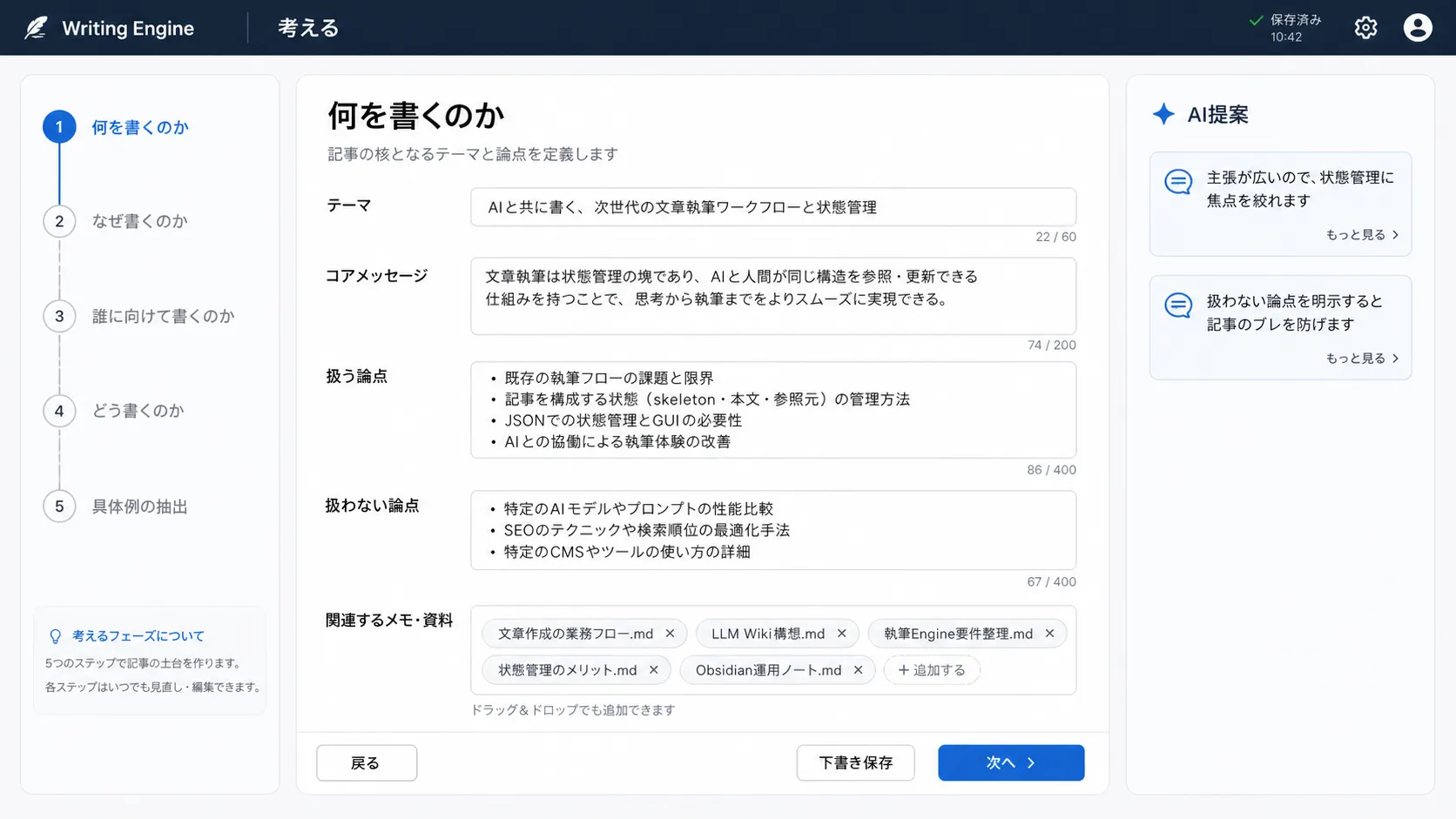
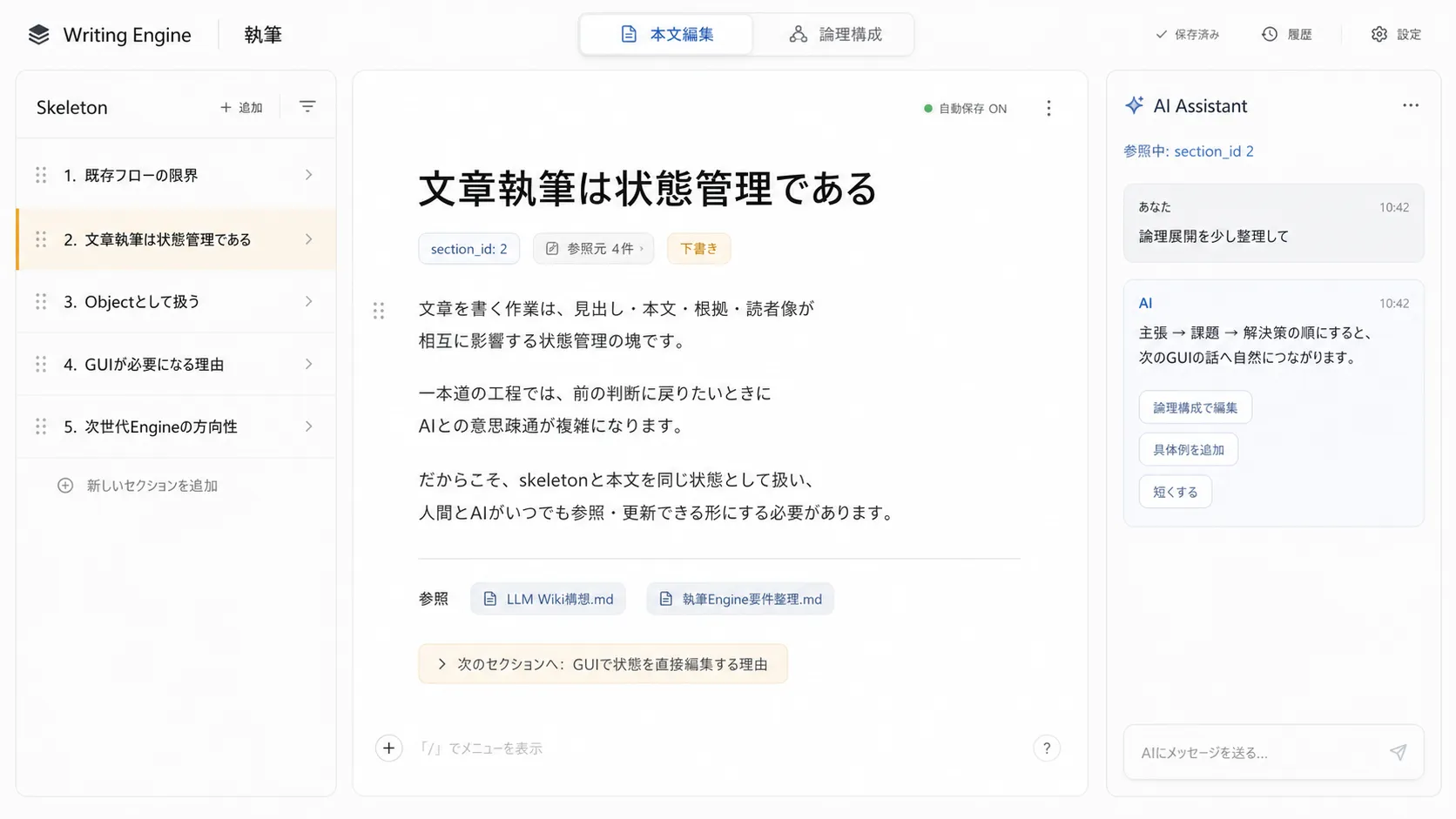
直接動かした方が早いものはマウス操作で、話した方が簡単なものは話して解決する。「AI で記事を自動生成する」という月並みな売り文句ではなく、まるで編集者に相談し、補助を受けながら執筆を進められるエディタがあればいいのではないか、と思った。
記事設計 (Skeleton) 編集のサポート・自動化
論理展開が外部の文献に依存するテキストは問題にならない & そもそも NotebookLM にでもお願いすれば 1 秒で片付きそうだが、今回の記事のように自分の体験談や一時ソースが中心となる記事については、自分で書くという作業を減らすのが現状難しい。
それでも記事設計に箇条書きで書いておくだけでいいので大分マシにはなっているが、6 千字を超えてくると内容がぐちゃぐちゃになったり不要な重複があったり、何を書いてるのか自分でわからなくなる・あと論理構成からひっくり返して詰め直したくなる等文筆家にありがちな発作の発症は避けられていない。
今回は、もともと PDCA + 5W1H 構成に寄せた下記のような構成だった。
# コンテンツ生成エンジンを作った話
## AIエージェントの登場でエンジニアの役割が変わる
### Prompt入力値の標準化
### この記事の位置づけ
## 何を作ったか
### LLM Wikiに接続されたコンテンツ生成エンジン
### 文章執筆というドメインの業務フローAI化
## なぜ作ったか
### 起点となった個人動機
### 書きかけのテキスト100Over問題
### AIで記事一発生成できる時代にわざわざ記事生成エンジンを作る理由
### 業務AI化のテストとして
## どのように作ったか: 設計と実装計画
### ドメイン言語化と Skills 設計
### AI ネイティブ業務フロー化
### プログラマ的設計の移植
### LLM 生成パターン把握の認識と改善
## どのように作ったか: 終わりなき出力調整事例編
### — v1〜v3 設計判断の地層
### v1 期: プロトタイプと言語化(2026-04-15〜04-18)
### v2 期: Issue 起点への転換(2026-04-19〜04-22)
### v3 期: 自己保身との戦いと部分巻き戻し(2026-04-23〜04-29)
### Check + Action — 検証要素ごとの重大事例集
## 振り返りと反省: うまくいかなかったこと
### 何でも自然言語+md でやればいいってもんではない
### 既存の業務フローがAIのボトムネックになる
### 説明しなくていい事を説明しなくてはいけないという問題
### データベースが存在しない業務なら、まずは大雑把に作っていった方がいい
## 振り返りと反省: うまくいったこと
### 機械的処理の自動化
### 文献収集・仮説実効性検証の自動化
### 階層的に精度を上げていくフロー設計
### プログラマ的設計判断
### 入力値の標準化
## 改善策と今後の展望
## 結章 — エンジニア 2.0 としてこのうち具体例は「終わりなき出力調整編」のみだ。具体例一切触ってない状態で一万字を優に超えるテキストに膨れ上がり、自分がいったい何を書いているのか訳が分からなくなってきた。そもそも構成が論理出来ではあるんだけど読みづらい。
執筆途中でもろにこの壁にブチあたり、読みやすい記事があるのでこれを参考にして、全面的に構成を見直したいと Claude に泣きついた。

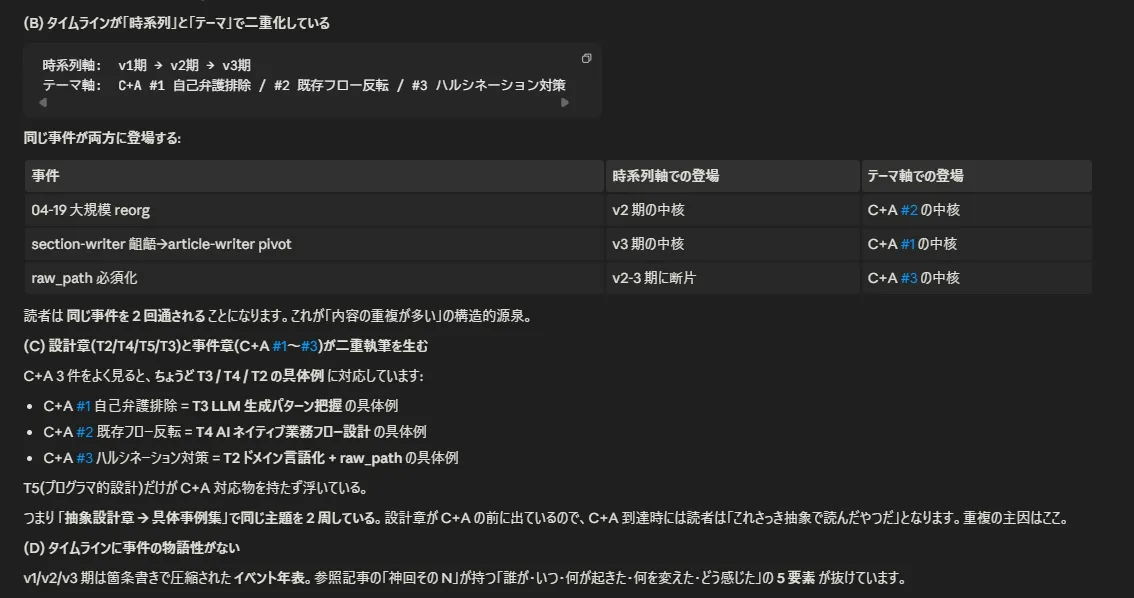
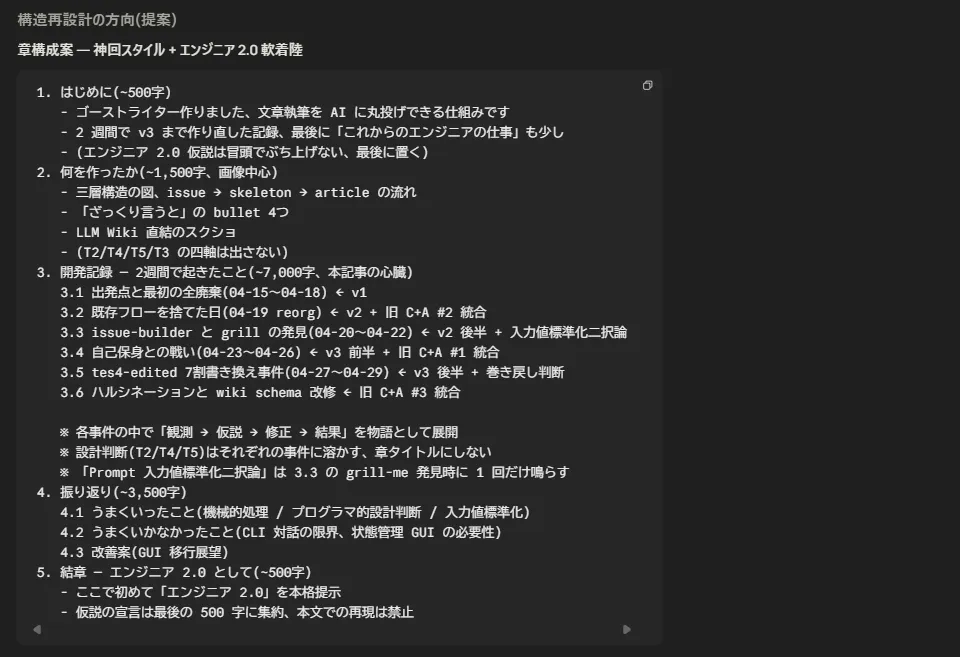
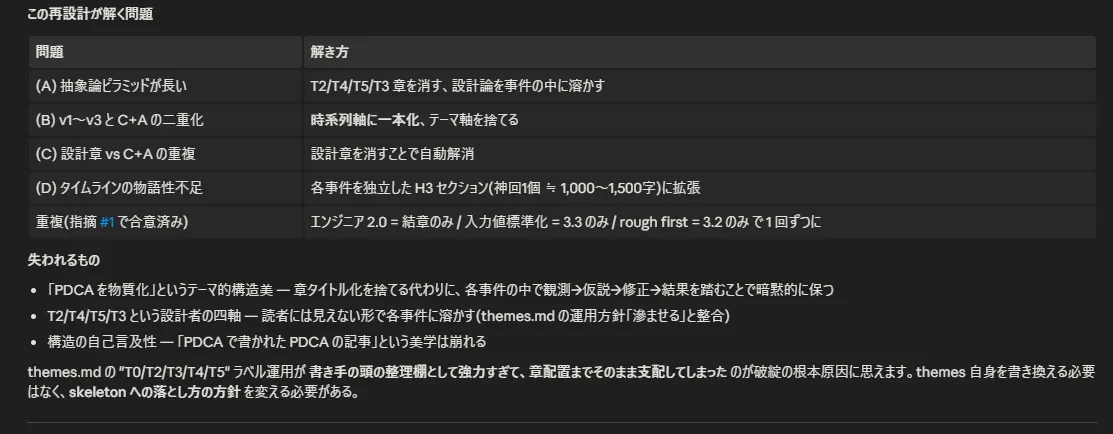
(何ひとつ文句言えない。人にダメ出しする時だけは常に優秀な Claude)
内容はすべて反映し、リライトした結果が今回の記事だ。全体的に具体例フェーズに寄せて抽象的な記述 & 重複箇所を削り、以降はスムーズに筆が進んだ。未解決事項ではあるが「できる」というのがわかったので、GUI エンジン化の際に盛り込むつもりだ。「こういうこと考えてて、こんな話を書きたいんだよね」みたいに話しながら記事構成・執筆を進めていければいいなと。それなら思考を整理・深めながら、記事を書く部分自体は自動化していける。
おわりに — 仮説の検証結果として
仮説に対する答え
ここまで読んで「なんかライティングの話皆無で、ほぼ業務フローをAI中心に組み直す話と、ドメイン知識をAIに教え込む話だよね」思っている方もいるだろう。自分もそう思うし、もしそう思っていただけたならこの記事の目的は果たせたのだと思う。
今回作ったのはコンテンツ生成エンジンだが、そこで起きていたのは文章執筆という特定ドメインの業務フローを AIネイティブに再設計する作業だった。ずいぶんと苦労はしたが、AIを中心に据えた業務フロー再設計する、という仮説は成立した。
今回の記録から得た 3 つの確信
何よりも食わせるデータがない領域・物事についてはLLMはそのままでは役に立たないということ。LLMは、2025年の初頭までに比べれば異次元の推論能力を得た。一方でLLMの推論は「膨大な量のパターンマッチングによる予測でしかない」というのは論理レベルで変わっておらず、AnthropicがいうようにSKillsで「ドメイン知識」を外付けで付与しただけで解決できるわけではない。だからどれほど推論能力が高まろうが、SKillsという思想が優れていようが、AIに食わせられるだけの一定量のデータ蓄積がなくては、LLMの真価を発揮させることはできない。
そのうえ、ドメイン知識があってもそのままAIには持ち込めない。だから検証サイクルを素早く回してどこまでがSkillsだけで完結するのか (AIエージェントとSkillsだけで表現できるのか) と、何がSkillsだけでは管理しきれないのかを洗い出すべきだ (反対にドメイン知識がなくても食わせるデータさえあるならば、ほとんどの領域でよい結果を得て自動化出来るだろう。皮肉な話だが)。
最後に、個人で使う場合を除いて、入力値の標準化は絶対に必要だ。対話シェルのような仕組みか GUI で、必要な情報を強制入力させる仕組みを組み込むべきである。今回はその検証としても、実証としても、一定の結果を得られたのではないだろうか。
コンテンツエンジン自体の話としては、効率化がすべてではなくて、自問自答をするように縦の思考を深める (思考の浅さを潰す) ための補助装置としてもAIは活用できるという事例にもなったと思う。
AI時代のエンジニアの仕事として
今回の試みはITエンジニアの「システムを作る」という仕事の枠から外れて、システム=業務を自動化する・ラクにする手段という本質を見つめ直したものだ。AIエージェントもシステム開発も、特定の業務を自動化するための「ドメイン駆動開発」だとしたら、エンジニアの知見が活かせる可能性があると仮定した。 同様に、これからの時代で「エンジニア」と呼ばれるのはこういった人物なのではないか、という仮説に基づいたものだった。事実として、海外ではマーケティングエンジニアなどと呼ばれる、今までは存在しなかった「業務ドメインを深く理解し、それをAIエージェントなどを組み合わせて自動化・最適化する仕組みを構築する 」新しいエンジニアの職種が誕生している。
かつては業務をラクにするために、システムを作ることで自動化するというアプローチだった。システムとは言ってしまえば画面の中で動くライン作業装置をつくって業務に組み込むということで、だから「作れる技術者」としてのITエンジニアの仕事があった。
しかし、今はどうだろうか?
高度なシステムなんて作らなくても、AIエージェントにいくらか指示を出せばすべて自動化できてしまう。そのために必要なのはドメイン知識や業務ナレッジだけで、母国語で説明さえできれば、それだけでシステムを作る以上の結果が成り立ってしまう。
だからこそ、いままで積み上げてきた技術者という自分のキャリアを一度すべてなげうって、ひとりのAIエージェントユーザーとしてAIと真剣に向き合わなくてはいけないと思った次第である。
結果として、エンジニアとしての経験は無駄にはならない事がわかった。 AIエージェントに業務ドメインを教え込むのには大量のデータかエンジニアリング的な視点が必要だし、既存の人間向けの業務フローもそっくりそのままAIに組み付けることも出来ない。だから何がゴールで、そこまでにどのような順番で情報が処理されていくのが最も損失・認知コストが少ないかという業務フローそのものの再設計が必要なのだ。どこまでがAIエージェントだけで実現できて、どこからがAIエージェント以外のコンポネート開発が必要なのかの線引きもしなくてはいけない。これはまさしく、特定のドメインを深く理解し、それを実装に落とし込むというエンジニアリングの仕事そのものだ。